
How much data do you think AI will create? In the last few decades, we've seen the data problem go from "how do I collect the data" to "how do store the data" and more recently to "uh oh I created too much data, how do I make sense of this."
As a product marketer for a data company, CastorDoc, I think about this quite a bit. The data ecosystem is already struggling with building understanding around data, a collective intelligence (1).
So, through all the excitement generated around AI, I can't stop thinking about the explosion of quick and easy content creation. This data has to go somewhere.
The evolution of information
As a species, humans are creators. This is our survival advantage. We didn’t evolve with giant teeth or claws; we evolved as problem-solving creators. From the first human to build a fire, pick up a stick to use a tool, and speak the first words of a language, it is necessary to create. Eventually, this desire to create turned to information to collect thoughts and ideas and make sense of the world around us.
In this case, let’s keep our definition simple and assume the idea of information starts with the emergence of writing. The first time humans began to collect and document thoughts likely started with tools like tally sticks used to count and mark quantities, going back 30 to 40 thousand years ago (2).
This likely started at an inflection point where social structures were becoming complex enough that pure memory didn’t suffice. Maybe they needed to share information across people or groups. Word of mouth didn’t cut it. Honestly sounds like a problem lots of small startups face. In short, some early humans needed to create information so another human could make sense of it or understand it.
The early tally sticks started as a low-effort information creation method, simply adding notches or symbols to bones or sticks. But as we already know, we built on this, ultimately forming advanced language and writing and moving on to more advanced distribution systems. The evolution of information has seemingly been a push and pull between the ease of information creation and the ability to understand or synthesize it.
With every new advancement, information creation requires less effort in the pure sense of physically creating it. However, as information creation has become easier, synthesizing it has become more difficult. It’s much easier to pull meaning from a tally stick than War and Peace. With AI’s emergence, we are now looking at another inflection point, where creating information is nearly effortless.
The information cup runneth over
AI can now create, parse, and manipulate large amounts of data, making creating information seemingly effortless. Is all the information correct or quality? Probably not, but it's information that is being stored somewhere, regardless. With the emergence of big data in the 2000s, we first stepped into the problems faced by the unfathomable amounts of data being created (3).
We answered that call by building data warehouses for storage and other cloud-based data tools to synthesize and visualize this data. And that was just for information created by humans and basic automation, vast but not on the same scale as AI capabilities.
With the advent of AI, we're witnessing a new dawn where content isn't just easily available but also cheap and quickly produced. But how much data will AI produce? We have barely scratched the surface of what generative AI will create. This endless data stream, while obviously valuable on so many levels, also presents new challenges.
We have reached a turning point where creating and distributing data isn't the problem. It's understanding and synthesizing it. Remember, this is already a problem in the data ecosystem for human-created data.
Still, AI will take this to a whole new level. Information overload is now a serious problem we will face. With AI churning out data around the clock, the risk of drowning in information has never been higher. The simple act of making sense of all this data is becoming an uphill task.
Here is how I visualize the effort required for information creation vs synthesis. Generative AI has put us at a critical inflection point, where the speed at which we can create data requires far less effort than our ability to make sense of it.
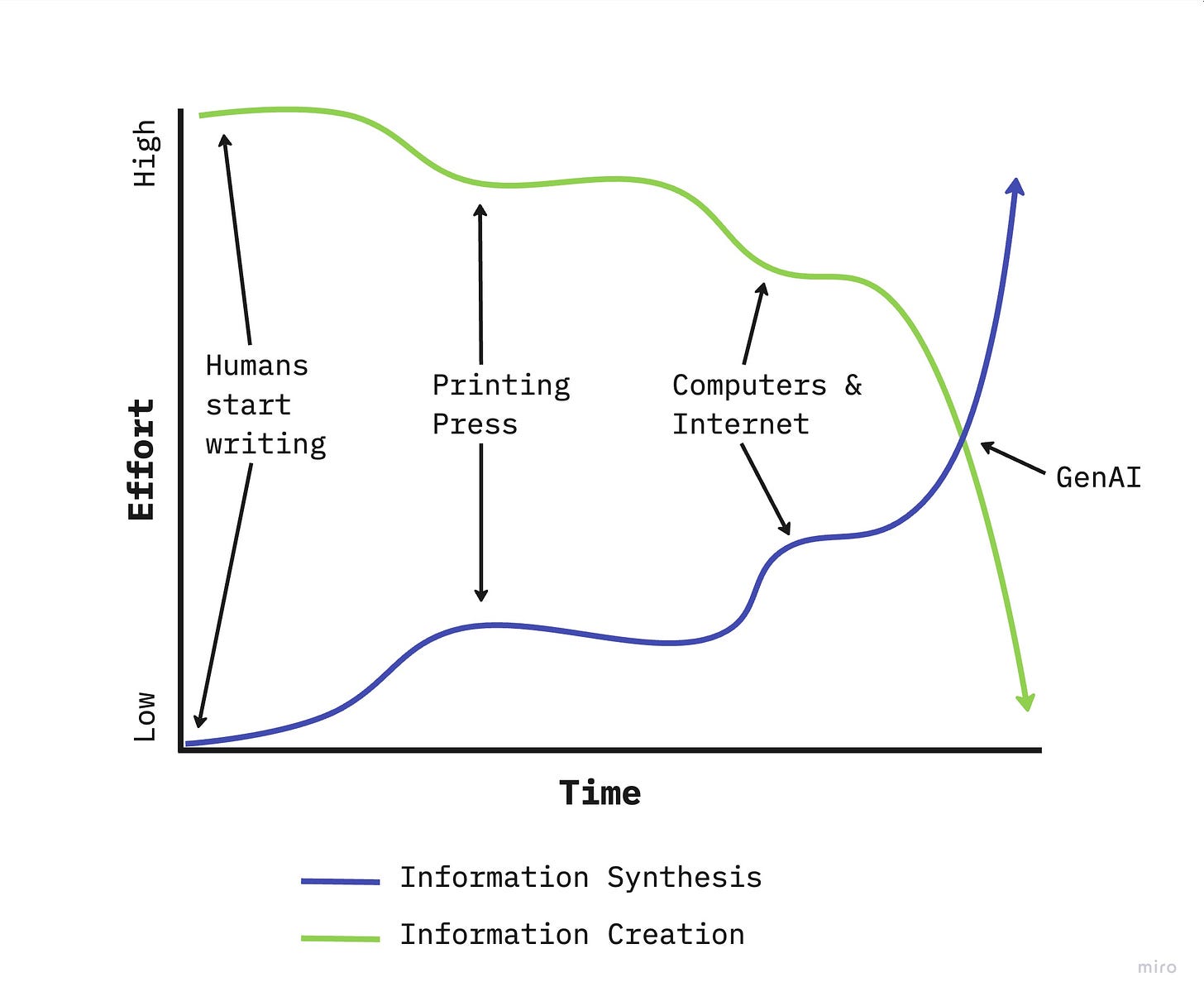
A completely (un)reliable chart I made based on absolutely human-created no real data.
In terms of information's evolution, the problem now isn't about creating information; we've got that covered, maybe even too well. Our new opponent lies in synthesizing this information into meaningful, digestible, and useful knowledge.
Making Sense of the Mess
With AI’s global impact, I think we are witnessing the onset of a new technological age, moving humans beyond the Information Age. Going forward, historians will talk about this moment in terms of before and after. In terms of us addressing the aspect of abundant information in this new age, the only viable solution here will be to build AI models centered around synthesizing data rather than generative models. Our problem isn't the lack of information anymore; it's too much of it. When you are presented with so many options, where do you even start?
This is a pure example of a signal-to-noise ratio (4). How do you make sense of all the information and weed out what's unimportant? The goal is to maximize the signal while minimizing the noise. But the catch is that the noise is loud, overwhelming, and coming from a new constant stream of AI-generated content moving at light speed.
In the next wave of AI, we will see more emphasis on increasing effort and understanding. We are already starting to see this discussed, with suggested SynthAI models over GenAI (absolutely).
With the rate at which AI advances, I see this coming fast. With the next milestones, it will be about not who can produce the most content but who can sift through it to find the wisdom.
The race is on, and synthesis is the next step.
1. Leyritz, Louise de. “Collective Intelligence: The Key to Building Better Documentation.” CastorDoc Blog, June 8, 2023. https://www.castordoc.com/blog/collective-intelligence.
2. “Tally Stick.” Wikipedia, April 12, 2023. https://en.wikipedia.org/wiki/Tally_stick.
3.“Big Data.” Wikipedia, June 30, 2023. https://en.wikipedia.org/wiki/Big_data.
4. “Signal-to-Noise Ratio.” Wikipedia, May 29, 2023. https://en.wikipedia.org/wiki/Signal-to-noise_ratio.
5. Zeya Yang, Kristina Shen. “For B2B Generative Ai Apps, Is Less More?” Andreessen Horowitz, June 21, 2023. https://a16z.com/2023/03/30/b2b-generative-ai-synthai/.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

