
This presentation was given by Anna Connolly (VP, Customer Success, OctoML) and Bassem Yacoube (Solutions Architect, OctoML) at the Computer Vision Summit in San Jose, April 2023.
In this article, we're going to focus on deploying models efficiently, particularly in the cloud.
But first, a little word on OctoML. We're a company of 100 machine learning systems experts who know a lot about infrastructure and how to deploy models, and we compile our experts from all around the world.
Our vision is a world where AI is sustainable, accessible, and used thoughtfully to improve lives. And we do that in a specific way by employing developers to deploy any trained model into an intelligent application in production anywhere.
Our founding team created the Apache TVM open source project and the XGBoost technology.
The challenges of deploying generative AI models
Anna Connolly
First, let’s just take a second to remind ourselves how ubiquitous AI is in the world today. This used to be a niche thing and now it's everywhere. It's in every application and in all the technology we're using. Models that were in academic papers six to eight months ago are now being talked about in the mainstream.
I was talking about ChatGPT at a birthday party last weekend. When your mom starts asking you about it, and when your kids and teachers are trying to figure out how to deal with this, you know that it's really broken through. And I think the speed at which all of this is developing is really incredible.
But what you all know is that this is a hard thing to do, to go from research into production, and to really make these apps usable for people.
One of our co-founders, Jason Knight, asked GPT-4 why generative AI models like the one that powers this app are so difficult to deploy. And the app dutifully returned a few key reasons.
Number one is performance considerations. In this specific talk, we're going to speak about performance in terms of speed of inference, latency, and throughput, and not issues of model accuracy or quality. So that's the first consideration.
The second one is compute constraints. Do you have enough of the hardware you need to deploy your feature or app and scale it up as demand increases?
And then number three is production costs. Is it economically viable for you to put this feature into production given the revenue or the traffic you might get from it and the cost to serve it?
Before we go into customer stories, we're going to look at these considerations in a little bit more detail.
Many applications require the lowest latency possible
Anna Connolly
A lot of computer vision applications require really low latency. There are offline batch processing use cases where throughput is the name of the game, but there are others where getting a model as fast as possible is the most important thing.
This can be because of user experience. Maybe you don't want your visitors to have to wait 30 seconds for their avatar to be created. Attention spans are short so you don't want them to click off a page or something like that.
But also for use cases like autonomous vehicles for object detection, this is super important for safety.
Models don't just exit the training process fast. There's a whole other set of things that have to happen to make them run really well in the hardware where you're going to deploy them.
Limited AI compute availability
Anna Connolly
The second is AI compute availability. You've all seen these headlines of empty shelves and the most powerful GPUs being unavailable for people who want them.
This is true but also not true, to a certain extent.
The most powerful GPUs that people are using for training, like NVIDIA A100s, are in short supply because they're increasingly being used for training large models and deploying large language models and inference.
But what's more available are smaller but still mighty devices like NVIDIA A10s, AWS Inferentia chips, and Google TPUs. These are really powerful, and if they're used properly, they can meet your SLAs and also be used in a much more cost-efficient manner.
The problem here is that the model code is tied to the hardware on which the model runs because of the training frameworks and vendor libraries, and you need specialized expertise to unlock this ability to switch from one hardware to another.
Model serving costs are going to rise and keep rising
Anna Connolly
Thirdly, model serving costs are going to rise and they're going to keep rising.
We like to say that training is a sunk cost. It happens once and maybe it happens again, but relatively infrequently. But inference costs are forever. And hopefully, if you're successful, they'll keep rising.
We can illustrate this with a quick story about incorporating a generative model into your app.
Let's say you're building an app for consumers who want to redecorate their houses. They upload an image of their living room, and maybe they can see different configurations of furniture or switch products in and out, and then they go and buy it.
And maybe your product manager comes to you when you're building this app and says, “Hey, instead of people selecting from a drop-down, I want them to be able to just type in a text prompt and redecorate in the style of a Tuscan Villa,” or whatever it is. And then you show the image and they can be on their way. That'll be a better user experience.
So you say, “I know this model. Stable Diffusion does this pretty well. Maybe we retain it a little bit, fine-tune it, and put it in production.”
But what you maybe haven't considered is that even if your app already has a lot of users or this feature goes viral, and you ramp up to tens of thousands of users in a month and they're each uploading a few images and selecting a few different configurations or prompts, you can scale your costs up to what you can see below.

If you're a small startup and you're incorporating this into your app, this can have a really big impact on your business model, your pricing plan, and how you fundraise. And you may not even know that when you're thinking through this.
How OctoML drives AI efficiency for its customers
Anna Connolly
At OctoML, what we're trying to do is help you take control of your AI destiny, find the right kind of configuration and efficiency for your models and hardware targets, and optimize them to minimize all these costs and make AI affordable, sustainable, and abundant.
Customer 1: Microsoft WatchFor
Anna Connolly
So now we can talk about customers. We’ve worked extensively with Microsoft, and this is one example of our work with one of their teams called WatchFor.
This team has built a digital safety platform and content moderation that's used by other business units like XBox, Bing, and LinkedIn.They process a tonne of video and image content - 4 billion frames monthly, and inference at this scale is super costly. They're spending a lot of money on it.
They came to us to increase automation and see what other kinds of cost efficiency they could get. And one problem they had is that their models could be deployed on any number of hardware architectures, from a very old CPU to a state-of-the-art GPU.
And figuring out the best configuration software library to use for each model in any of those circumstances is really time-consuming, hard to benchmark, and hard to configure. So they wanted to get more automation into that deployment process.
The Microsoft WatchFor team are expert users of a technology called ONNX Runtime. It's a machine learning open-source accelerator that Microsoft produced. So of course, they also leveraged it, which means their models were pretty well optimized to begin with. They were already running pretty fast.
We helped them use Apache TVM, which is a compiler-based approach, to get increased throughput because unlike the low latency use case we were talking about before, throughput and batch processing is really what's important to them for a number of their models on both GPU and CPU, and then to benchmark and help them determine the best way to deploy the rest of their suite.

We were able to achieve 2X faster model performance, 94% savings on certain CPU run models, and 23% on GPUs.
I think the quote below really illustrates what many of our customers say about working with us. For some of the hardest machine learning systems problems that they have, they're able to just leave that to us and allow their developers to focus on tasks that are more important and beneficial to the company, like building a better application, understanding their users better, and more efficient tasks.

Now, Bassem’s going to talk to you about a generative AI case.
Customer 2: Wombo
Bassem Yacoube
Hi, everyone. So the next customer project we're going to talk about is Wombo. Wombo is now the world's most popular AI lip sync app. They have over 100 million downloads on the App Store, and they use generative AI for a number of use cases.
One of the new features that they're planning to release soon is the ability to let the user select and upload an image of a celebrity and send a certain text message. And then they're going to generate a video of this celebrity saying that message.
As you can imagine, this is something that's very compute-intensive. They started testing a few generative AI models on their own, like Stable Diffusion, text-to-video, and the FILM model. Then they came to us to work with them on trying to accelerate these models and get any efficiencies there.
The model that we worked with them on first is the FILM model. FILM is an open-source model created by Google. It stands for ‘frame interpolation for large motion.‘
You give this model two images and it creates a video of the morphing or the interpolation between those two images, from image A to image B, using the number of frames that you specify.
The way we optimized the FILM model was by running that model on our platform.
Our platform does a sweep of different hardware targets and different machine learning runtimes, creates all these experiments, and benchmarks the model for you, giving you the different latency and cost for this model on different hardware with different runtime back ends.
The other thing it tests is the runtime environment. We try several different runtimes, like ONNX, ONNX with CUDA, ONNX with TensorRT, OpenVINO, TensorFlow runtime, and our own Apache TVM.
One thing I want to mention is the way these optimizations are done. It's a very deep, technical field, and there’s still a lot of research going on. But it uses operations like kernel tuning, quantization, operator fusion, and tensor fusion. These are just a few examples.
If you want to learn more about this, you can check out our website and go take a look at the TVM documentation. There are a lot more resources on how exactly this stuff is done.
But from our experience working with customers and their engineering teams, creating those experiments and running them could take several hours to several days to create each one, because just getting these environments ready with all the dependencies, getting your containers, getting your test harnesses, and timing the performance correctly isn’t an easy task.
The good news is that you don't have to do any of this. You can just upload your model to the OctoML platform, and we’ll automatically run all these experiments for you and give you the models with the best results on the best hardware and the best runtime.
For the FILM model, these are some of the results that we were able to get:

If you assume that we’re doing 15 frames for an interpolation of two images that are 1568 x 972 resolution, and doing that by using the baseline model, which is TensorFlow plus CUDA on an A100 GPU, this is what we used as our original baseline. That takes about 10 seconds.
After optimizing the model, you can run it on an A10, which is a lot cheaper and a much more available instance, and it’ll take about 2.7 seconds to do the same interpolation.
It's almost 4X speedup, and we don't do anything that affects the model accuracy. Our tool just basically runs at the layer where the model instructions get compiled into machine code that runs on specific hardware. Your model doesn’t get altered and your accuracy stays the same, which is finding faster ways to execute on your target hardware.
We improved the latency by 4X, and if we translate this into cost, assuming you're doing 1,000 images on the A100 using the baseline time, you’d be paying about $11.50.
If you do the same 1,000 images on an A10G, it’ll cost you less than a quarter of $1. So that’s 98% cost savings, which for somebody building an app that, for example, is going to do 10,000 images a day over a year, that's the difference between $43,000 and $800.
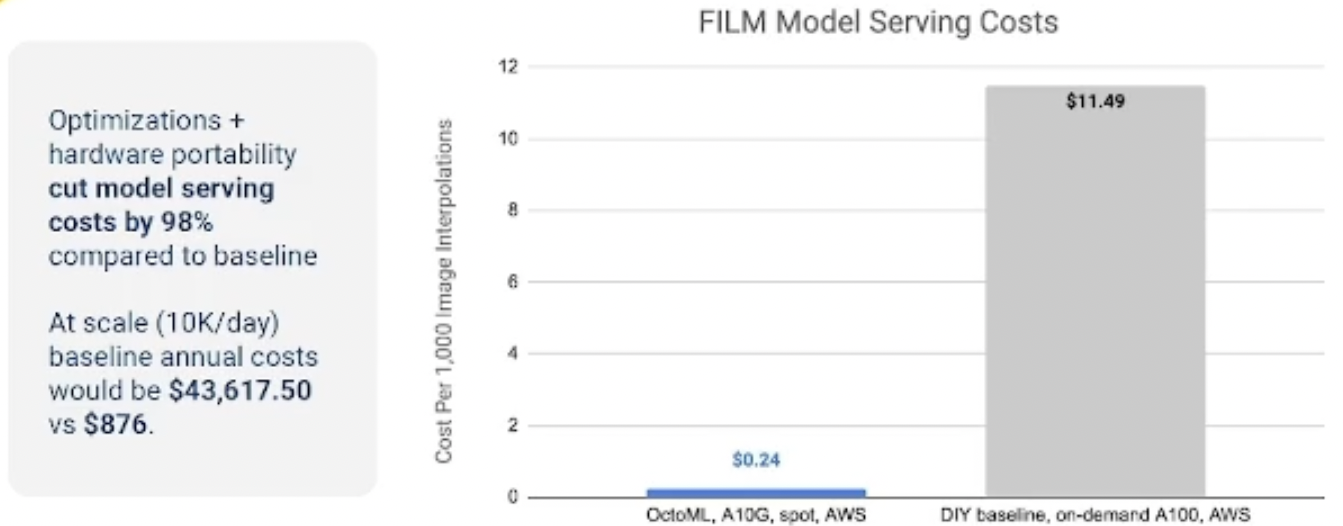
It’s a huge impact on the bottom line. But that's not the only benefit that Wombo was excited about. The time saving itself is very valuable because that could mean that they could award more users on this new feature without having to pay more for their cloud usage.
They can also do more frames and have the videos be smoother and have a better resolution. Or they can just improve the user experience. Instead of having to wait 30 seconds, they're going to wait less than 10 seconds.
So these are all benefits you can get with a platform like OctoML, that optimizes your model automatically and tells you the best hardware target and best runtime for them.
OctoML’s AI compute service
Bassem Yacoube
The last thing I wanted to tell you about is that we're introducing our AI compute service very soon. This’ll be a cloud AI service; it’ll allow you to upload your model and get it optimized and deployed to any cloud of your choice. And you'll just receive an endpoint that you can use directly in your application.
In addition to that, we're also going to be accelerating several foundational models and publishing those as out-of-the-box endpoints like Whisper, Stable Diffusion, and so on.
Below are the results that we got just this week on Stable Diffusion 2.1. We were able to accelerate it by almost 3X. It’s so much faster than any Stable Diffusion app that you've played with before.

Solutions for your AI journey
Anna Connolly
Just as a wrap-up, we went through the problems you’re all probably facing in getting your models deployed and in production. We also went through some solutions for customers.
Our goal is for you to never even be aware of these problems. Do you even care what software we're using to optimize your model? You just want something fast and you want it easy, and that's what we aim to give you, so you don't have to worry about what hardware you're running on.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

