
This article is based on Santosh Radha’s brilliant talk at the AI Accelerator Summit in San Jose. As an AIAI member, you can enjoy the complete recording here. For more exclusive content, head to your membership dashboard.
Generative AI is revolutionizing how we interact with technology. From chatbots that converse like humans to image generators producing stunning visuals, this incredible tech is transforming our world.
But beneath these mind-blowing capabilities lies a massive computing infrastructure packed with technical complexities that often go unnoticed.
In this article, we'll dive into the realm of high-performance computing (HPC) and the challenges involved in productionizing generative AI applications like digital twins. We'll explore the explosive growth in computing demands, the limitations of traditional HPC setups, and the innovative solutions emerging to tackle these obstacles head-on.
But first, let me quickly introduce myself. I'm Santosh, and my background is in physics. Today, I head research and product at Covalent, where we focus on orchestrating large-scale computing for AI, model development, and other related domains.
Now, let’s get into it.
The rise of generative AI
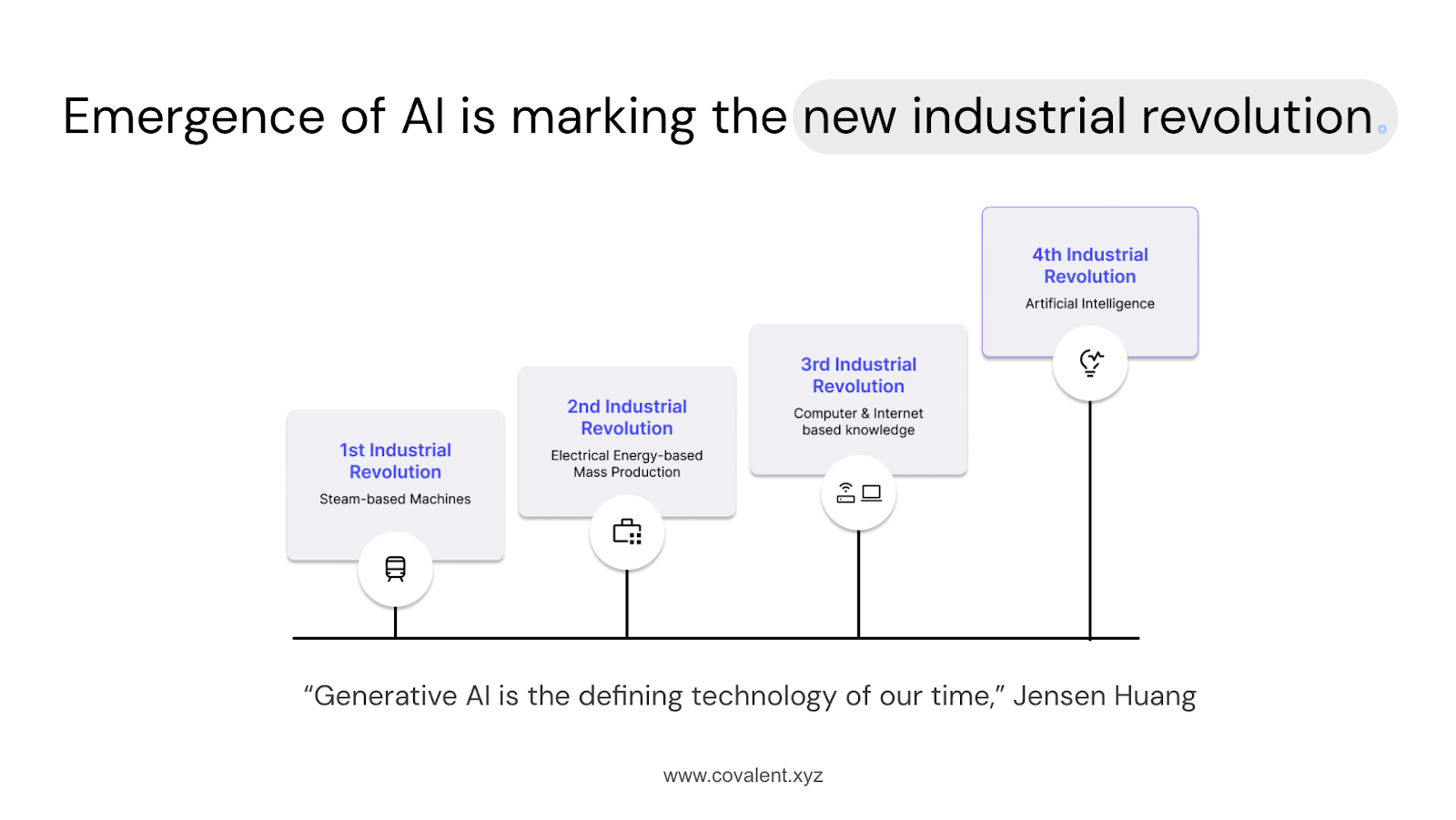
Recently, at the GDC conference, Jensen Huang made an interesting observation: he called generative AI the “defining technology of our time” and termed it the fourth industrial revolution. I'm sure you'd all agree that generative AI is indeed the next big thing.
We've already had the first industrial revolution with steam-powered machines, followed by the advent of electricity, and then, of course, computers and the internet. Now, we're witnessing a generative AI revolution that's transforming how we interact with various industries and touching almost every sector imaginable.
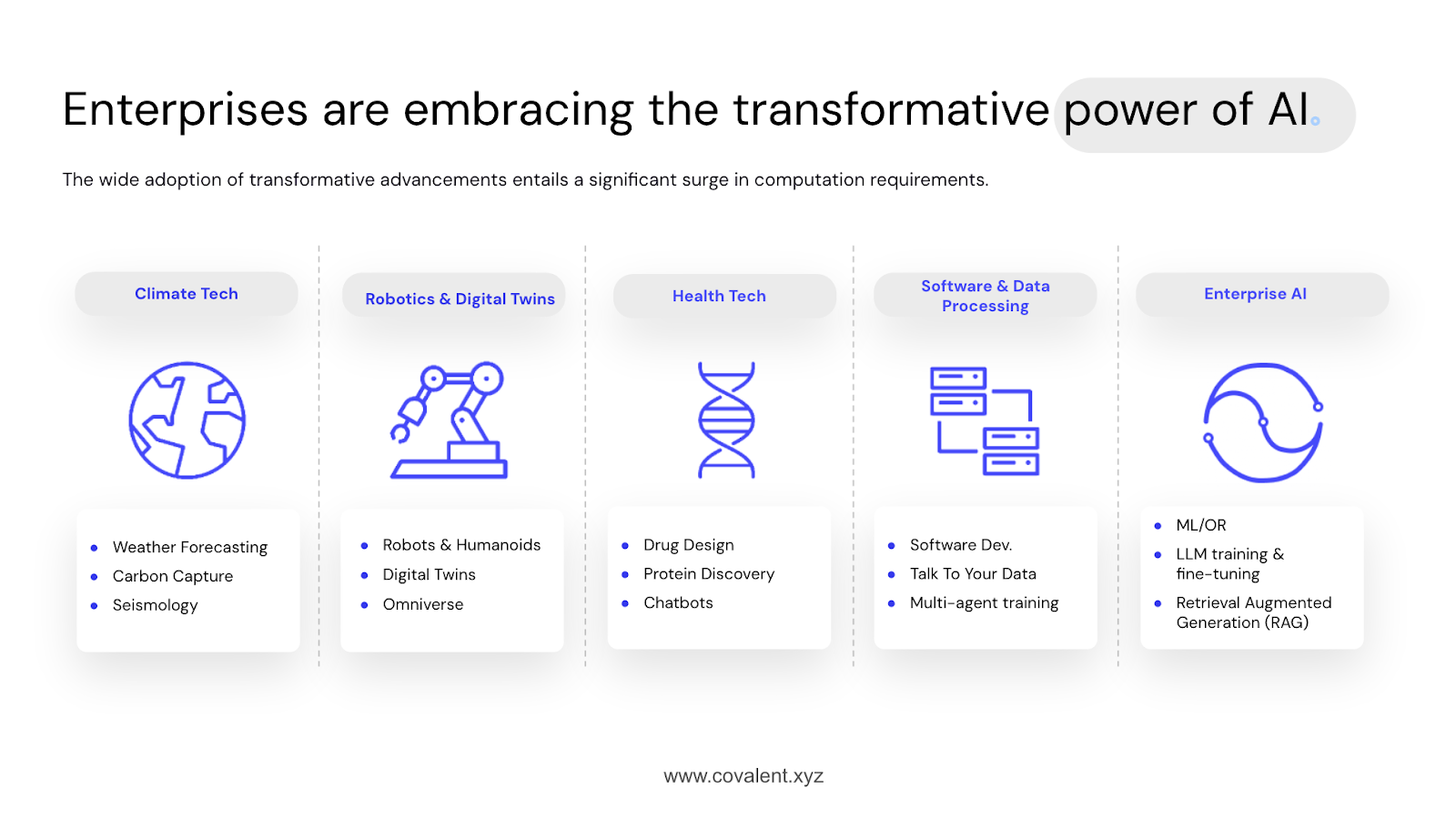
We’ve moved beyond machine learning; generative AI is making inroads into numerous domains. It’s used in climate tech, health tech, software and data processing, enterprise AI, and robotics and digital twins. It’s these digital twins that we’re going to focus on today.
Digital twins: Bridging the physical and virtual worlds
In case you’re not familiar with digital twins, let me explain the concept. A digital twin is a virtual representation of a physical system or process. It involves gathering mathematical data from the real-world system and feeding it into a digital model.
For instance, let's consider robotics and manufacturing applications. Imagine a large factory with numerous robots operating autonomously. Computer vision models track the locations of robots, people, and objects within the facility. The goal is to feed this numerical data into a database that a foundational AI model can understand and reason with.
With this virtual replica of the physical environment, the AI model can comprehend the real-world scenario unfolding. If an unexpected event occurs – say, a box falls from a shelf – the model can simulate multiple future paths for the robot and optimize its recommended course of action.
Another powerful application is in healthcare. Patient data from vital signs and other medical readings could feed into a foundational model, enabling it to provide real-time guidance and recommendations to doctors based on the patient's current condition.
The potential of digital twins is immense. However, taking this concept into real-world production or healthcare environments presents numerous technical challenges that need to be addressed.
The computing power behind the scenes
Let's shift our focus now to what powers these cutting-edge AI applications and use cases – the immense computing resources required.
A few years ago, giants like Walmart were spending the most on cloud computing services from providers like AWS and GCP – hundreds of millions of dollars every year. However, in just the last couple of years, it's the new AI startups that have emerged as the biggest consumers of cloud computing resources.
For example, training ChatGPT-3 in 2022 reportedly cost around $4 million in computing power alone. Its successor, ChatGPT-4, skyrocketed to an estimated $75 million in computing costs. And Google’s recently launched Gemini Ultra is said to have stacked up nearly $200 million in computing expenditure.
These staggering figures highlight how the computing costs traditionally incurred by major enterprises over decades are now being matched or exceeded by AI startups within just a couple of years.
From Anthropic to OpenAI, DeepMind, Hugging Face, and countless others, the underlying force driving their breakthroughs is the availability of massive computing power, albeit at astronomical costs.
To truly grasp the scale we're dealing with, let's look at the exponential growth in computing power used for training large AI models over the years.
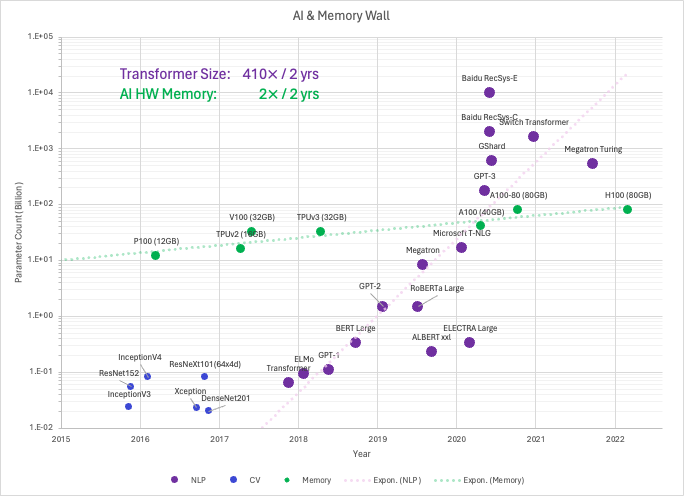
The green line in this graph represents the computing power used by GPUs from 2016 to 2022 - from the V100s to the latest H100s.
As a rough estimate, training the GPT-3 model on a single A100 GPU would take a staggering 355 years! Clearly, relying on just one GPU is practically impossible for models of this scale.
The reality is that training these massive foundation models requires harnessing thousands of GPUs in parallel, leveraging billions of compute hours in extremely distributed setups. This level of complexity is mind-boggling when you consider that we're just chatting with these AI assistants without realizing the tremendous effort behind building their underlying models.
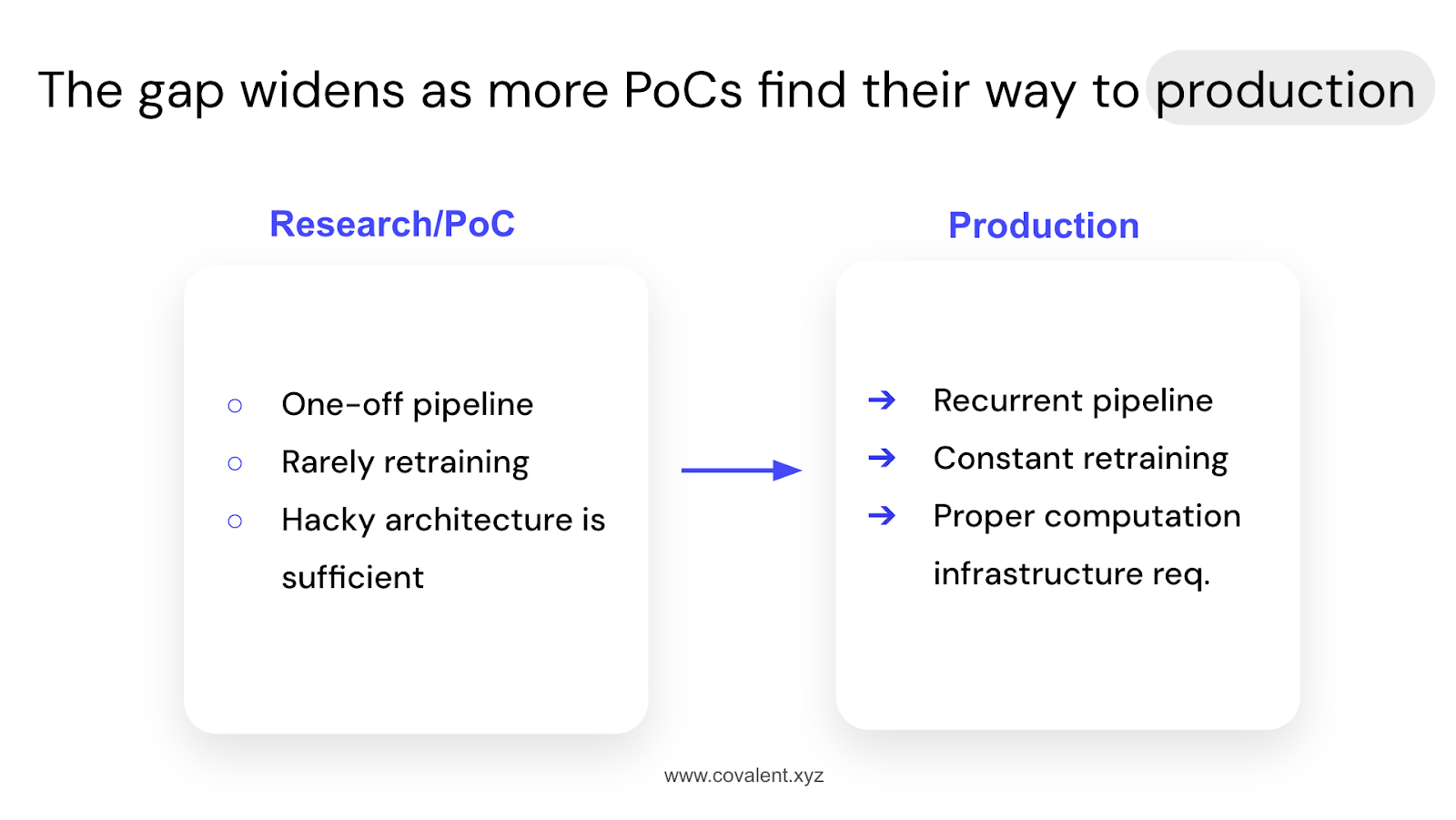
The current state of generative AI has been predominantly focused on research and proof-of-concept (PoC) work. To undertake such endeavors, organizations typically assemble teams of around 100 engineers to code the model, procure the necessary computing resources (often costing $20-30 million), and then initiate the training process.
At companies like OpenAI, my friends describe going through around 10 different approval checkpoints before someone can finally press the button to kick off a $25 million computing run that continues training the model for several months.
If you’re thinking, “Wow, that sounds like a lot!”, you're right, but here’s the kicker: all this complexity is merely for the initial training phase or building a PoC. Any subsequent iterations, like moving from GPT-3 to GPT-4, require rethinking and rebuilding the entire architecture, rewriting all the code, and rescripting everything from scratch.
Productionizing AI: The next frontier
While the model training phase itself is extremely resource-intensive, the real challenges arise when deploying these large language models and digital twin applications into production environments like real-time healthcare monitoring or smart manufacturing setups.
This involves a constant pipeline of model training, retraining, and updating to keep up with the dynamic needs of these use cases. As you can imagine, this can get pretty costly, both in terms of the computing power and the financial resources required.
As I mentioned earlier, training these massive models doesn't happen on a single GPU, CPU, or even a single cluster. Instead, it requires thousands of GPUs working in unison across distributed computing setups.
Distributing tasks across multiple cores, processes, and clusters is standard practice in fields like drug simulations, chemistry modeling, weather forecasting, and other academic fields.
While this level of high-performance computing (HPC) was a niche requirement in the past, there’s been a transition over the last few years. HPC is now taking center stage for mainstream industries and applications adopting AI at scale.
However, several critical challenges arise when building foundation models or other high-compute applications leveraging HPC infrastructure:
Challenge #1: Exclusive access to compute resources
Currently, even accessing a modest amount of high-end GPUs – say, ten H100s to train a relatively small model – is an uphill battle. It typically involves waiting months, proving your use case, and then reserving those resources for a couple of years through cloud providers. On-demand access is extremely limited due to the very nature of high-performance computing.
Challenge #2: Outdated tech stacks
The tech stack traditionally used for HPC workloads is, to put it mildly, quite outdated. This is because HPC has primarily been an academic domain for decades. Many of these HPC clusters still run code written in Fortran – a programming language developed in the 1950s.
In contrast, the bread and butter of modern machine learning and AI stacks is Python. Unfortunately, the existing HPC infrastructure doesn’t integrate well with Python workflows. Concepts like Kubernetes and dockerization are largely absent from these setups.
Challenge #3: Massive inefficiencies
Recent research has highlighted that when running models on traditional HPC systems, only 30 to 50% of the computing power is being used productively.
The remaining 50 to 70% essentially goes to waste due to the mismatch between the underlying infrastructure and modern AI workloads. Translated to cost, this could mean millions of dollars being flushed away in underutilized resources.
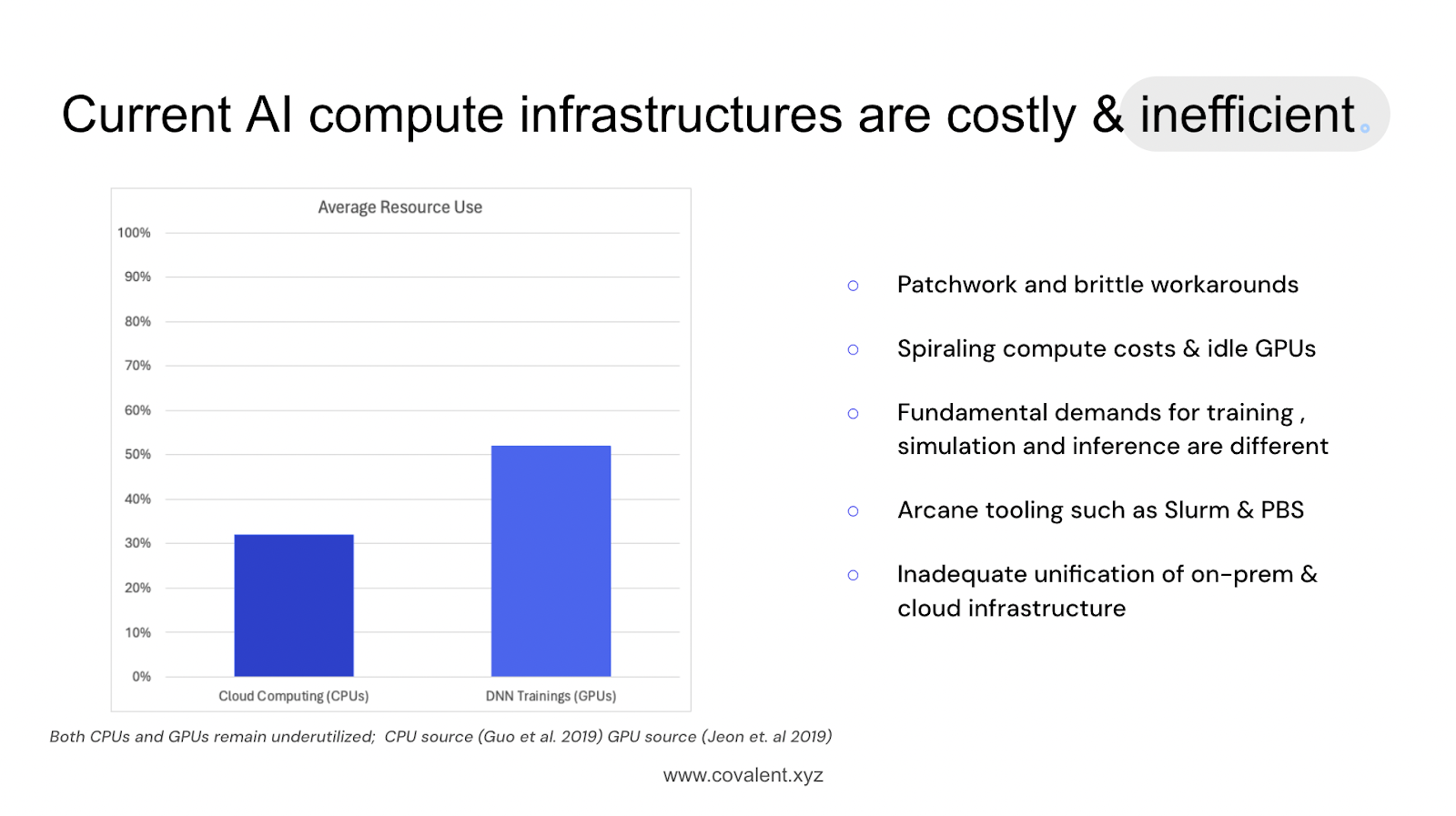
There are ongoing efforts to address these inefficiencies. People are taking novel approaches to GPU utilization, interconnects, and hardware-level optimizations. However, this remains an active area of research and development.
It's not just the monetary costs that are concerning - GPUs are extremely energy-intensive as well. Some of the GPU clusters found in national labs require the equivalent electricity consumption of a small town to power and operate. Given this level of energy demand, we need to ensure maximum utilization of available GPU resources to minimize wastage.
The solution: Orchestration
Traditionally, enterprises have partnered with individual cloud providers like AWS, GCP, or Azure to procure compute resources. However, in today's era of generative AI and digital twins, compute requirements are so immense that a multi-cloud setup is no longer just an option – it's a necessity.
To access the hundreds or thousands of GPUs needed, organizations can't restrict themselves to a single cloud platform. They need to span multiple clouds, on-premises data centers with in-house GPUs (which can be more cost-effective than cloud rental), and even tap into specialized GPU clouds from providers focused on this domain.
This hybrid, multi-cloud environment presents a significant architectural challenge – how do you design a cohesive solution that orchestrates all these disparate compute resources into a unified, scalable, and cost-effective production platform?
Covalent's orchestration solution aims to tackle this very problem. By seamlessly integrating and managing compute infrastructure across clouds, on-prem, and specialized providers, we enable organizations to build and scale AI/ML applications leveraging the combined power of all available GPU resources. If this sounds good to you, feel free to head over to our website to find out more.
Key takeaways
We’ve covered a lot of ground today! Let’s recap with a few key takeaways:
🚀 Generative AI has been dubbed the fourth industrial revolution, with digital twins and other groundbreaking technologies poised to disrupt industries.
💻 Today, training the latest language models and generative AI apps means harnessing thousands of GPUs and billions of compute hours across distributed setups - pushing modern computing infrastructure to its limits.
⚠️ Traditional high-performance computing environments face major hurdles like exclusive resource access, outdated tech stacks, and massive inefficiencies – all major roadblocks to productionizing generative AI.
🌐 Orchestrating resources across multiple clouds, on-prem data centers, and specialized providers is a must to meet the colossal computing demands of generative AI at scale.
💡 Bridging the gap between cutting-edge generative AI models and real-world deployment means rethinking and overhauling the underlying computing infrastructure challenges.
⚡ Innovative solutions are emerging to tackle generative AI's technical complexities, including optimizations for GPU utilization, interconnects, and hardware-level advancements.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

