
Edouard Naegelen (VP of Sales & Customer Success, SmartOne) and Hadrien Jacomino (Key Account Manager, SmartOne) gave this talk at the Computer Vision Summit in London in 2023.
Edouard Naegelen
SmartOne is a data labeling company and has been working for the biggest tech players around the globe for over ten years.
We’ll be talking about why data is the only thing you should have if you want to create, scale, and industrialize an AI solution. We're going to explore that with a concrete use case of one of our customers.
- SURGAR: Enhancing surgical precision with augmented reality
- The data dilemma
- Creating and preparing data sets for an AI model
- The best way to do data labeling at scale
- The three Ps of successful data annotations
- 4 key successes in the surgical AI project
- A quality assurance process is critical
- Data labeling is the bottleneck of any AI project
SURGAR: Enhancing surgical precision with augmented reality
Here’s what our customer, SURGAR, is doing and why data is very important to them:
Every year, more than 15 million surgeries are performed worldwide using laparoscopy. This minimally invasive surgical technique is used for abdominal procedures and offers various advantages for the patient.
However, it also presents serious challenges for the surgeons, such as the loss of eye and hand coordination, and the loss of tactile feedback. This explains why laparoscopy is only used for 30% of abdominal surgeries.
At SURGAR, we want to bring laparoscopic surgery to the next level, thanks to visualization software overlaying the real-time surgical video with 3D augmented reality images, showing the organs' internal structures.
Before surgery, using SURGAR plan software, a first phase of image segmentation is carried out using MRI or preoperative scanner images to create a 3D model of the organ and its inner structures.
During surgery, a digital twin of the organ is created. Algorithms using a deep neural network allow for automatic detection of the organ limits and the segmentation.
Developed with surgeons' ease of use in mind, SURGAR is simple to operate and doesn't require any additional viewing headset.
Our preclinical studies have proven that we increase surgical accuracy by a factor of 20 and decrease complications by twofold using SURGAR software.
No more classical mental mapping approach for the surgeon with the associated mental burden of rebuilding 2D info into a 3D format; SURGAR will create a new segment market of laparoscopy, assisted by augmented reality.
Edouard Naegelen
Through this example, let’s understand why clean data is the bottleneck of every AI project, and why building an AI model is almost all about data and also some volumes.
The data dilemma
Whether a model is annotated with 400 images, 4,000 images, or 40,000 images, the quality of the output is completely different if you train the model with a small amount of data compared to a huge amount of data. The recognition of the disease and the organs are completely different, and in healthcare, you don't want to have low quality.
AI is a combination of code, computing power, and data.
Let's say that computing power and code have been the main challenges of the last decade. Now, if you go on GitHub, you have almost every model you want. If you want computing power, you can go to NVIDIA or Microsoft and you can buy almost unlimited computing power at an affordable price.
When it comes to data, it's much more complex. You may have the raw data set, and you may have time to label some images, but at the point you want to scale your model, most people struggle here.
Now, here’s the paradox - data labeling takes up 80% of a job, or at least of the time needed to create a model, but no one likes to do it. Ultimately, it's boring and repetitive. But it's crucial. At the end of the day, it's what makes your model work in real life.
Coding the model is quite fast, provided you have the right computer model and partner. And then you'll struggle with preparing the data, finding the data, and sometimes you don’t even have the raw data so you need to create a data set and look at who’s going to build your dataset.

It's not only a question about a classic raw data set. To have a perfect data set to train a model, you need to have a few categories. You need a large volume, it needs to be high quality, and you need to be compliant. You can’t do whatever you want with the data set.
For example, in Europe, you need to be GDPR compliant, or you need to have specific certifications if you want to process medical images in the US.
The data set also needs to be contextualized. And here, it needs to make your data speak, learn your model, understand how to react, and what to say in these particular situations.
Creating and preparing data sets for an AI model
Contextualized or labeled data to fuel AI is solving a six-variable equation, and you need to answer these when you create and prepare data sets to train your model:
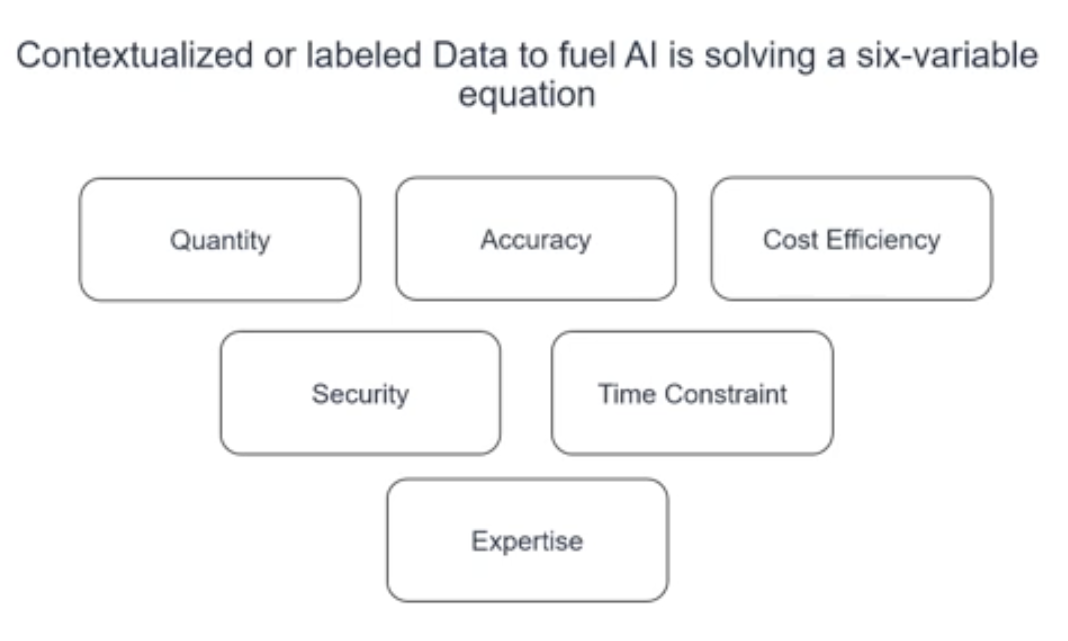
The first part of the equation is that you need to be quantitative and you need to be accurate. If you want to have a highly quantitative output, the input also needs to be highly quantitative.
It needs to be processed in a full, secure way, and most of the time it needs to be processed for the next day because you want to have your model display as soon as possible.
You also need to have the best expertise because everyone has a particular area of an industry where only their expertise is necessary to label a data set.
It should be also as cheap as possible.
To make it happen, you need two things. First, you need tools. There are several tools out there that can help you label your data set. The problem with this is that software companies usually only give access to one tool, which often can’t help you with multiple projects.
Secondly, you need humans. Even though generative AI is improving fast, you still need people to control the labeling.
The best way to do data labeling at scale
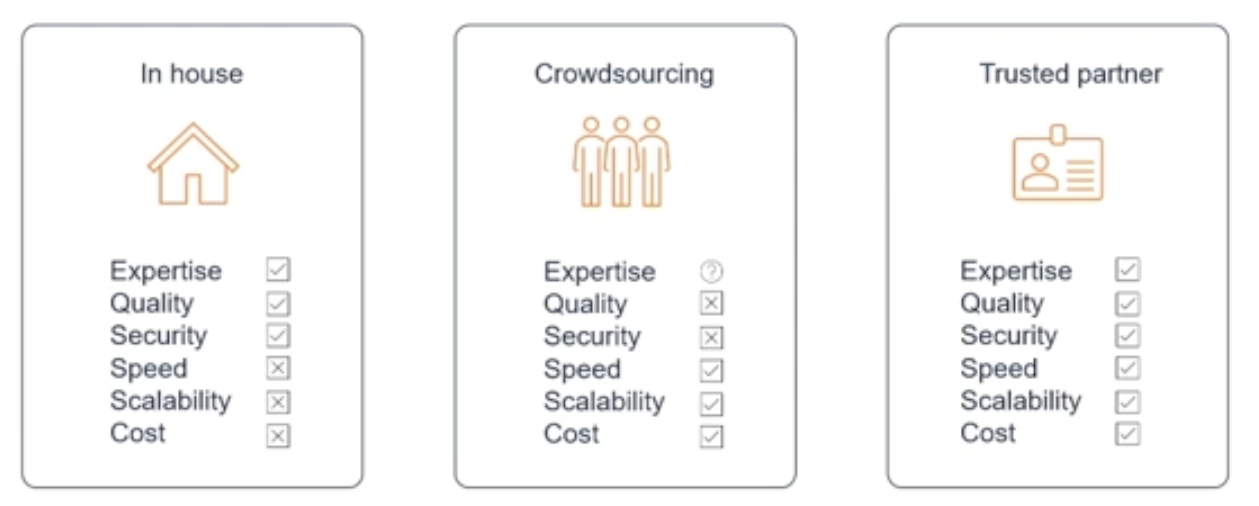
There are three possible solutions you can explore with humans in the loop.
The first one is doing the data labeling in-house. You’ll have the best expertise, the quality will be great, and the security will be perfect. But it won't be quick because you're not used to doing data labeling all day long. It won't be scalable because you have a limited team and you can’t scale from let’s say 1,000 images to 100,000 images. Plus, it’ll be costly.
The second solution is crowdsourcing. For me, this is the wrong solution because the data simply isn’t secure. You don't know who’s going to label the data, and you don't know if it’s even an ethical way of doing the data labeling.
The third solution is relying on a trusted partner. We can guarantee the expertise, the quality, security, speed, scalability, and the cost. For us, it's the only way to do data labeling at scale.
So, let's explore that through the use case of SURGAR and what the output of that was.
The three Ps of successful data annotations
Hadrien Jacomino
I’ll show you how collaboration works between us and our customers through a use case.
It's important to keep in mind here that there are two entities. One of the entities is SURGAR, which is the solution provider; they provide computers to the surgery rooms. And then there’s us, SmartOne, who’s doing all the annotations.
The idea is that one day, they’d come to us and say, “We've got some scientists, but we don't have a lot of time to do data annotations. We're working on maybe 400 images, but this isn’t enough for what we want to do because we've got a lot of different projects. We want to work on different organs and we don't have a lot of time to do that.”
“What we can do right now is good for a university study, but we can't really scale and keep that pace. So how can you help us do that? We've got a huge batch of thousands of images, how can we do that together?”
So they’d come to us and we’d work together to scale that and organize the project.
There are three Ps that are taken into account. The first one is people. All of our operations are based in Madagascar; the company was founded there, and we've got roughly 1,200 people. They have to keep in mind that there’s a multicultural aspect that needs to be taken into consideration for the project.
All of them have been working for the company for a long time, and they all have different expertise in terms of tools, what they can do, classification, segmentation, as well as the sector they work in. Are they working in healthcare? Are they working in tech?
The second P is process. We have various teams, and they say, “Okay, we need to allocate the best people for the task.”
We say, “You have your guidelines, your model, and your data set, but what we want to do is provide you with an all-in-one solution, meaning that we have a training team and we’ll train all the annotators internally, and then train on a daily or weekly basis depending on the requirements of the project.”
We also have a quality team because quality is getting more and more important.
Everyone's collaborating internally to get to the final goal, which is having proper, qualitative data sets.
The final P is the platform. There are different aspects to this. We can propose a platform.
We partner with different platforms, so we say, “Okay, now that we've been working on the market for 10 years, we think that this platform might be better for your task, and this platform might not be as good.” And we can provide a lot of analytics.
So, the idea is to have a platform but to have real-time analytics. What am I annotating? When will I deliver this amount? How can I do that? We need to give them the best features they might need for the project.
 Ana Simion
Ana Simion
4 key successes in the surgical AI project
There were four elements that made the success of the project.
The first one was truly understanding the need. This might sound simple, but when you have such a sensitive use case like surgery, you need to be sure that you understand everything. You might think that you just need a labeler, but you need to decide who the best person is to do that.
So they’d come to us and say, “We need doctors,” because if you’re on the surgery table tomorrow, you don't want the solution to be annotated by random people who aren’t doctors.
So the idea was to evaluate the quality of the doctors versus the annotators, and if you want the solution to go to the market, you need to have everything approved.
So we ran some tests on some expert annotators and some doctor annotators, and the outcome was that the expert annotators were better than the doctors.
The reason for this is when you're a doctor, you know the surgery process and you're not going to be taught your job by a labeler. But you've got your own way of working, and a specialized annotator will go through everything by pixel level and they’ll be much more accurate in terms of what’s needed for the model.
In the end, we decided to go with only expert labelers to work on all the datasets. The other important thing to keep in mind is you can do that, but in the end, it needs to be approved by a doctor, otherwise, you can't really control and validate your model and put it on the market. So the need was to get everything approved.
In terms of the tool, in this case, the customer had the platform they were working with, along with the small data set. So they could say, “We have the platform, it's already set up, and it's fine for us because we've already worked on it. And if it's a new platform, we can learn and even if there are some specificities, we can easily adapt to that.”
There was an important process to respect so we could go through all the phases. This was custom-made, and in this case, we had to implement some exams, validations, and tests: level one, level two, a general exam, and an exam specialized on any organ we were going to work with.
When an annotator goes through all the tests and they’re approved, they can start work on the project. You can’t just read the guidelines, get trained, and start working on it right away.
And then we ran a strong quality control system.
Juliette Denny
A quality assurance process is critical
The first phase of the quality assurance process is the production phase. You’ll have all the data on the platform, the labelers are going to work on it, and then it's going to be processed and validated.
The second phase is the data analysts. They're going to gather all the data, make sure that it's available in any format you may need, and then send it to the people who are responsible for the quality.
And then this is where quality control happens.
The quality team is independent, so it's very important for these people not to be linked to the production because we want to avoid bias and they need a proper way of looking into the data.
Because the data was tackled by the data analyst team, we did several samples. There are different ways to perform that. We implemented all the ISO regulations so we had a very detailed way of sampling all the data.
You can have an individual level where you say, “This isn’t good enough, you need to be trained again.”
You also have a team level, where as a whole, the data is good or not good. So you can have a lot of different reports helping to evaluate the quality in the end.
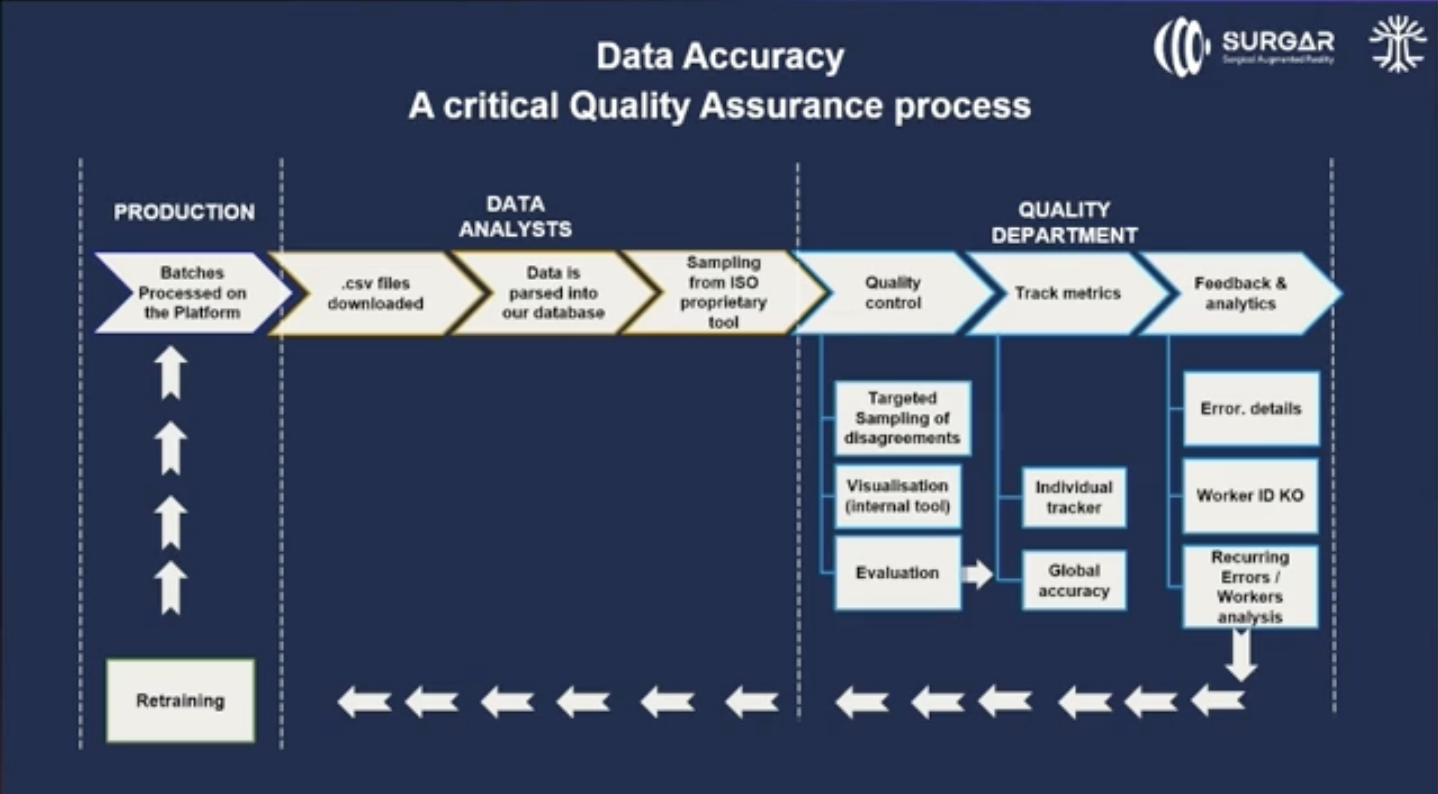
When this is done, the batches go to the customer and they can say, “Okay, we're going to sample again. If it's good, this can go out on the market, if it's not good, it needs to go back to you.”
Before that, if the sample isn’t good enough and doesn't reach 98% or 99% internally, then it goes back to the first production phase because we evaluated internally that the data isn’t good enough to be delivered to the customer. Of course, we try not to do that too often because it's very costly.
This is the best way we’ve found to guarantee very high levels of quality. Quality is becoming more and more important these days and the jobs we do require more expertise and in-depth analysis.
Data labeling is the bottleneck of any AI project
Edouard Naegelen
There are three key takeaways as to why data labeling is the bottleneck of any AI project.
The first one is that a good labeling tool is nice, but without humans, it’s worthless.
The second one is that a non-expert workforce can do better than experts because an expert is an expert at their own job, but not in data labeling at the pixel level. For example, they might know where to draw the lines from a uterus, but they don't know how to perfectly segment the uterus at the pixel level to be used by a computer.
And the last one is, before starting any kind of project, the question isn’t where you’re going to find some code and a data labeling solution, but who’s going to label your data? How are you going to do that internally?
So when you go to your VC or your board, say, “Hey, guys, I have an idea, but I know exactly how to deploy this idea.”
Download the Generative AI report today and find out how companies are using the technology.



AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

