
Let's start by talking about what Airbus Commercial Aircraft does. We're in the business of building commercial airliners, and in a typical good year, we’d build something in the order of 700-800 aircraft.
The aircraft are assembled in what's called a final assembly line, where all of the parts that Airbus and other suppliers have made are brought together. We're talking about fuselage sections, wings, engine pylons, and the tail. All these things come together and are assembled into a final product.
We also understand the standards that are involved in aerospace. It's something where it needs to be done right, and it needs to be good.
A lot of my focus at Airbus is on the analytics pipeline. This is looking at how we can collect data in the real world on the shop floor during the manufacturing process, and how that data can be processed using algorithms to generate analytics, which can then power applications to help real people make real decisions.
But today, I really want to focus on the processing aspects of this.
How does self-supervised learning work?
To start with, I want to do a thought experiment. Now, I'm not an expert on children. But as far as I'm aware, they're really good at learning new things.
For example, if you're trying to teach a child something and they see a dog and a cat for the first time, you can go to them and say, “This is a dog, and this is a cat.” You can show them lots of different examples of dogs and cats, and they're pretty good at understanding that there are two distinct types of animals. “This is a class of animal called a dog, and this is a class of animal called a cat.”
We're also probably very familiar with this application of computer vision, building a convolutional neural network that’s capable of discriminating between cats and dogs.
However, unlike a child, a convolutional neural network might need to see hundreds of examples of each animal to be confident and get the same level of performance as a child.
This ability to learn very quickly from little data is really interesting for us as data scientists because personally, I hate labeling data. And it's not just that I hate labeling data, but often there'll be situations where we have far more data than we can ever label.
I want you to imagine that you work for a company and your boss comes to you and says, “We've got a million images of steel plates and some of these steel plates have defects, but we've only managed to label 1% of the steel plates.” So say we've got maybe 10,000 examples, but we've got a million images of steel plates.
In a conventional way of working, what we’d do is build a classifier and train that on those 10,000 examples. But we wouldn't be able to leverage those 990,000 other examples that we have at our disposal. It’s unlabeled data.
So this is potentially where SSL could come to the rescue. And I want to quickly go through some terms because I think it's really important at the outset to make sure that we're really clear about what different words mean.
- Supervised learning: all of our data has labels
- Semi-supervised: only some of our data has labels
- Unsupervised: none of our data has labels
- Self-supervised: none of our data has labels, but we engineer our own
But what is self-supervision? It's a form of unsupervised learning where the data itself provides the supervision.
In general, we withhold some part of the data and then task the network with predicting it. The task itself defines a proxy loss and the network is forced to learn what we really care about, for example, a semantic representation in order to solve it.
So the current practice is where we'll take a network that’s been pre-trained on a very large data set. For example, we might take a model that's been pre-trained on ImageNet and then fine-tune it on another task.
We might have the challenge of building a network that can identify different types of aircraft. So we might want to identify the Airbus A320, the Airbus H130, the Airbus H350, or the Airbus H380 in an image. So what we'll do is take a labeled data set where a number of different examples of each aircraft are labeled and train our model on that.
So, what's wrong with human-annotated supervised learning? Well, a large class of contemporary machine learning methods relies on human-provided labels as the only form of learning signal used during the training process. This overreliance on direct semantic supervision has several perils.
For example, the underlying data has a much richer structure than what the sparse labels can provide. We often require large numbers of samples to learn from and converge to solutions. It leads to task-specific solutions, rather than knowledge that can be repurposed.
It’s also expensive producing a new data set for each task, and it can often be very challenging in some domains. For example, medical data or manufacturing provides enough annotation.
We also have this huge untapped availability of imagery data. For example, there are a billion images uploaded to Facebook per day, and 300 hours of video are uploaded to YouTube every minute.
As I mentioned before and alluded to, probably most intriguingly, it's how infants may learn.
Compared to the traditional workflow, how does the self-supervised workflow work? To give an example, let's say that we still want to build an aircraft classifier. Instead of having to label all of the images, we might have a million images of aircraft of all different types. What we could do is take all of the unlabeled imagery and then use a pretext task and self-supervised learning to train a model to solve this pre-text task.
We could then take the weights of the network or network that's been trained, and fine-tune that on a subset of the imagery which has been labeled. So this in turn could give us superior performance than what we’d have had if we'd used this traditional method.
Turning away from computer vision for a minute, I think it's really interesting and instructive to briefly look at the history of NLP.
I'm sure that many of us are aware of the huge breakthroughs that have happened over the past couple of years. Looking at the chart below, we can see the huge improvement in performance that's occurred as a result of the BERT revolution.

BERT is a form of self-supervised learning where the algorithm undergoes pre-training using a closed passage-type task. Below we can see a paragraph of text that's somewhat relevant to me. You’ll see I've redacted some of the words, but as humans, we can infer what the words are.

This is pretty much one of the tasks that are used to help train BERT, where a paragraph of text is fed in, words and tokens are removed, and then BERT has to predict what words should go into each slot.
Now, that's enough talking about NLP, let's turn our attention back to computer vision.
How to adapt SSL for computer vision
One of the challenges for applying self-supervised learning to computer vision is that fundamentally there's a big difference between Natural Language Processing (NLP) and computer vision.
In NLP, when you remove a word from a sentence, there's only a finite number of other words that could go into that slot. In the case of computer vision, we have millions of other images that could be generated when we remove part of another image if we start to look at things on a pixel-by-pixel basis.
So when you think about an image, it might have three color channels and there might be 256 different values for each pixel. So you can understand from a combinatorial basis just how many different other possibilities there are for what could go where. So we really have to get a bit more creative when we start looking at how we can create these surrogate proxy tasks we want to carry out.
Now, there’s this really rich legacy over the past couple of years of people engineering really clever ways to come up with different tasks. For example, if you've got a movie, you could reorder the frames so that becomes a combinatorial problem to reorder them.
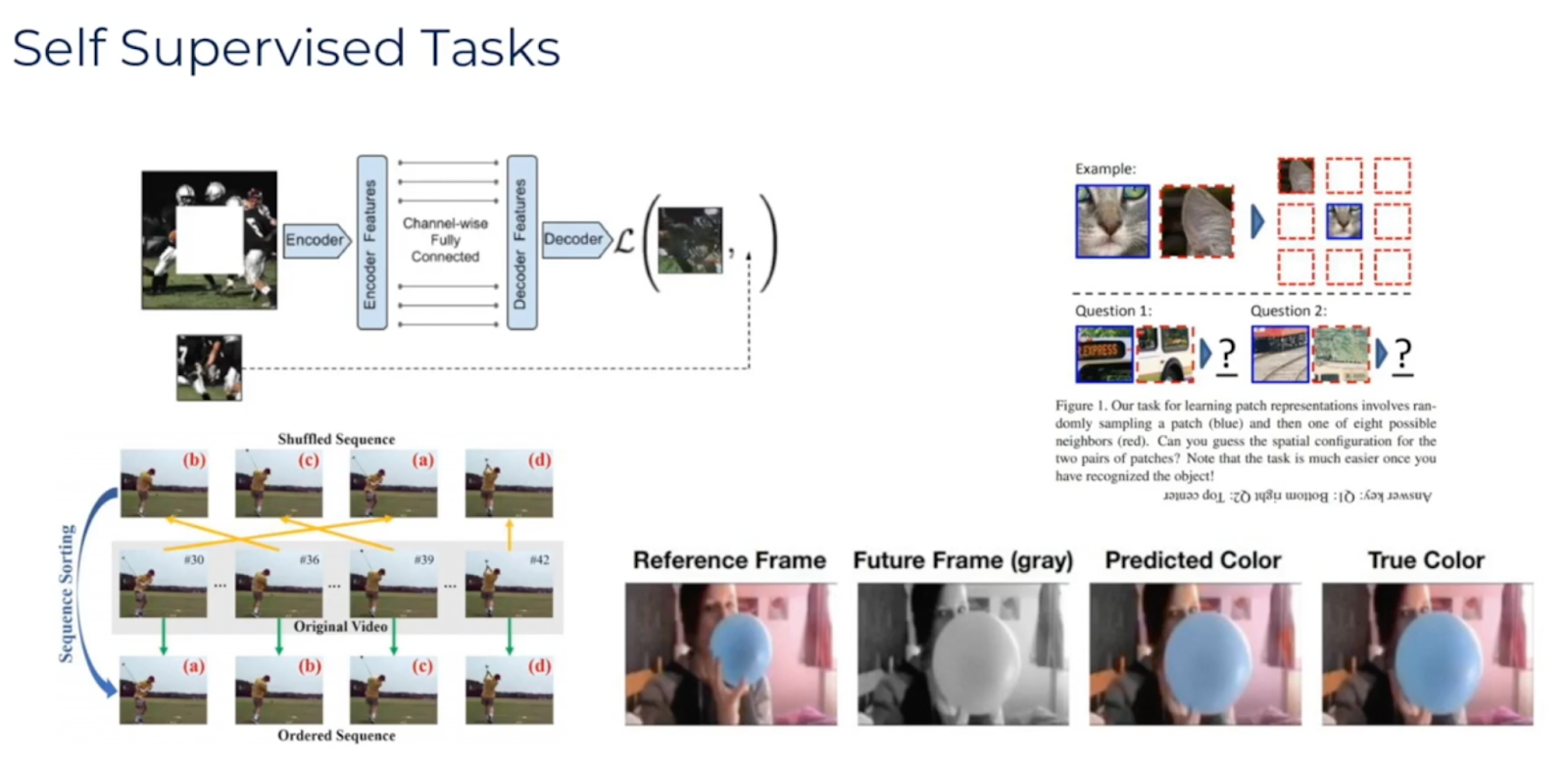
You might have an image where you slice and dice it up and you've got these different parts, so then it's like a jigsaw and you need to rearrange them back into position.
You've also got other tasks. For example, you might decolorize a frame and then have to predict the color of the frame. So there are lots of different tasks like this that have been engineered.
But at our core, what we're trying to do is engineer a representation. So we might have an image that’s this million-dimensional vector and we're trying to crunch it down to a representation. And what we want to do is generate representations where images that are semantically similar end up with similar representations.
Even if our representation was a very high dimensional vector, if we use the techniques, say UMAP or t-SNE, to map it down to two dimensions, what we’d want to see is images that are semantically similar.
On the left of the image below, you can see there are two images of a plane, where there's a different likeness in the image. On the other side, you can see two images of a different plane in a different situation where one of the images has been flipped right and the color balance has been changed.
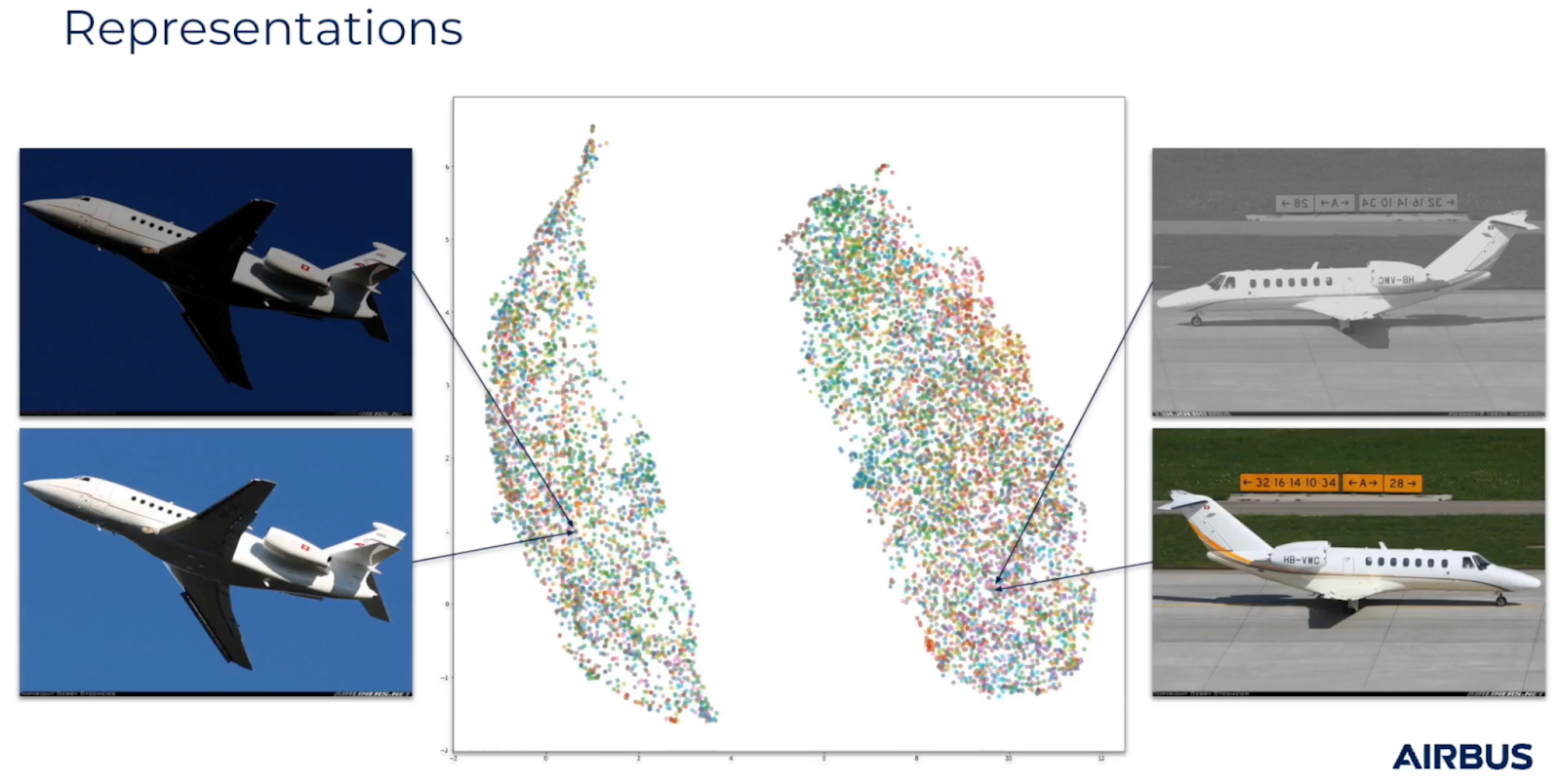
The images of the same aircraft are semantic with the same object being mapped to the same point in space.
I now want to deep dive into some of the components that you'll find in a typical setup for self-supervised learning, in particular, the network, the augmentation, and the pretext task.
In terms of the network, what we're really focusing on is training these convolutional filters. We're trying to learn weights and biases that will generate useful representations for our data set.
What I mean by this is that we feed in imagery, and then we want to try and learn the different concepts so that similar concepts will be mapped to similar points in a much lower dimensional space. So really, we've got this form of dimensionality reduction, where all we need to do is learn these filters so they give us the best possible representations.
Now, while the network itself that we're training might be fairly standard, like a ResNet-50, where it becomes really interesting is in the pretext task. And this is where a lot of the creativity comes in and a lot of the research has been done.
There are a number of different state-of-the-art methods, including contrastive learning, different Siamese architectures, and redundancy reduction which is Barlow Twins, which I'll talk about in a little bit.
There are lots of different papers that have different strategies underpinning them. I don't have the time to go into each of them because there's a lot of complexity that's involved, and we're at the stage where we're learning what works and what doesn't We're really looking for that silver bullet for a solution that’s simple and works well.
I'm not sure if Barlow Twins is that silver bullet, but it’s certainly very promising and it's beautiful in its simplicity. So let's now focus on that in more depth.
A deep dive into Barlow Twins
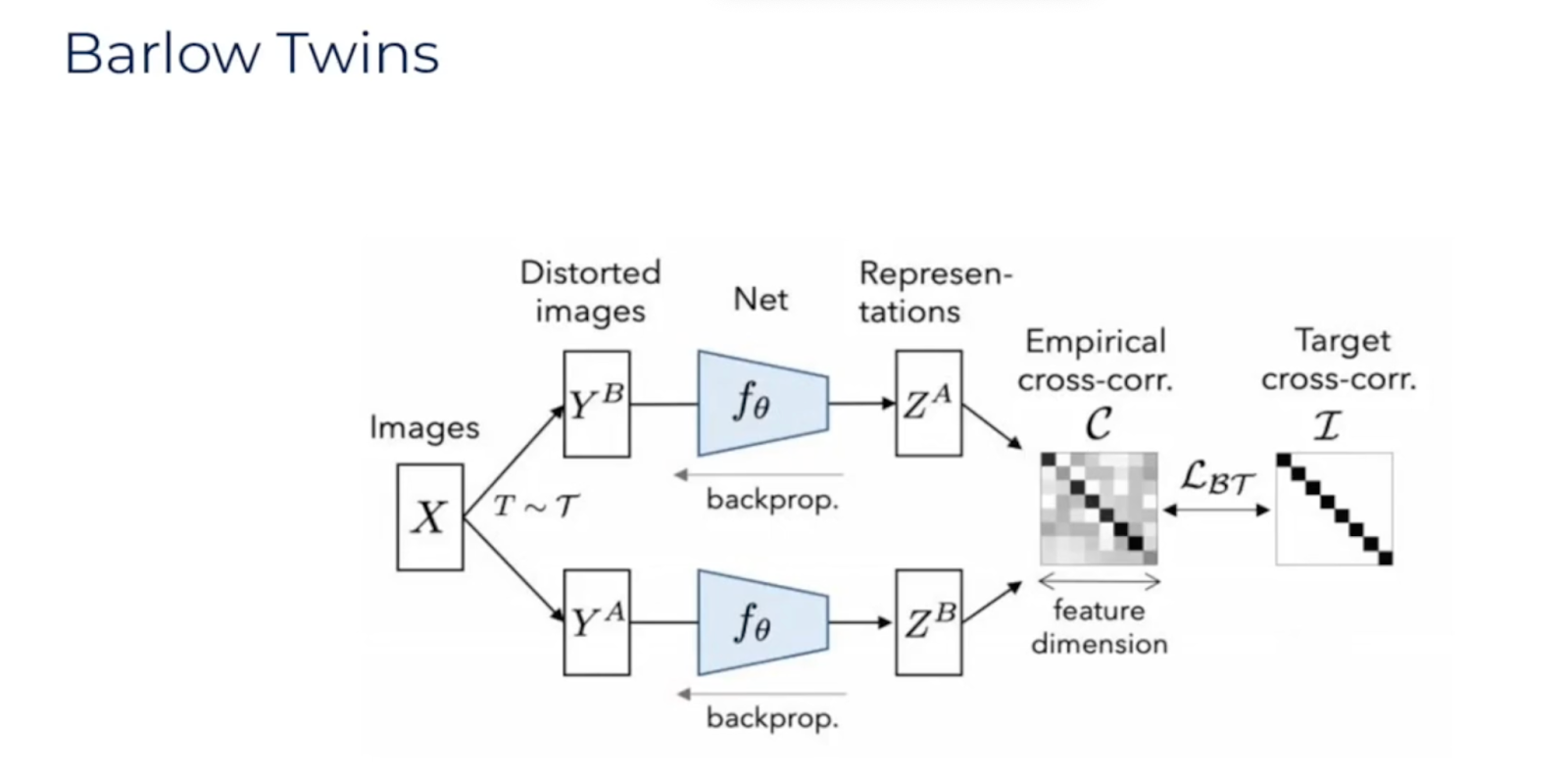
At a high level, we start by drawing a batch of images, let's say 24 images. We then augment this batch twice. So we'll generate say, an A batch with one set of augmentations, and a B batch with another set of augmentations that are different.
We then feed each image in the batch through our ResNet-50. And just to specify, this is what's known as the Siamese network. So we've got two identical networks that are linked together. Both the weights and the biases are identical.
On top of the ResNet-50, we've got an MLP that generates a representation, which you can see above marked as representation ZA and ZB.
What we then do for all of the images in the batch is compute the cross-correlation (I'll go into more detail later about how this is done) between the representations of all of the images in the batch.
Now ideally, what we want is to generate representations with minimal redundancy. What that means is that for the two matching images that are fed through our Siamese network but have been differently augmented, we want to generate identical representations. However, we want the representations for different images in the batch to be as different as possible.
But why is it so important? Why are we doing all of this with the cross-correlation? Why do we want there to be as little redundancy as possible?
Well, one of the challenges is if we're trying to train a network to generate the same representation for the same image, what can go wrong is that the network could learn it can get a very, very low loss just by mapping every single image to have the same representation. We have this collapse.
So, in summary, the aim is to make the outputs as close as possible to the identity matrix. And we want to minimize redundancy between the different vector components.
Why is this important?
Taking a quick thought experiment, if we only wanted the network to learn that differently augmented input images should have the same output vector, what could happen is the network could learn to map all images to the same output vector. So what this means is we’d have a really low loss. And this is something that can happen with earlier, different networks.
So as I mentioned before, what we do is draw a batch of images. For each image in the batch, we augment it twice in two different ways.

We then feed it through a ResNet-50 network, and we generate a dense representation from our input image. We've got two different networks which are both identical, so this is our Siamese network.
Then for each image in the batch, we generate the cross-correlation of its vector representation. If you're unsure what cross-correlation means, here's a very quick example below.

What we do is compute the dot product between each combination of vectors and then normalize that. So if we've got two vectors, A and B, and we want to compute their normalized cross-correlation, we can compute the dot product, and then divide by the length of A times the length of B.
What's beautiful about Barlow Twins is its simplicity and elegance. It’s also incredibly effective.
Let's take the situation of trying to train on ImageNet, where we've got 1,000 different classes. What happens if we try and train a supervised model on only 1% of the data? Well, we can see that can get an accuracy using a state-of-the-art model of about 25%. Using Barlow Twins, pre-training on all of the data without the labels, and then fine-tuning on that 1% of the labels get us to 55% accuracy.
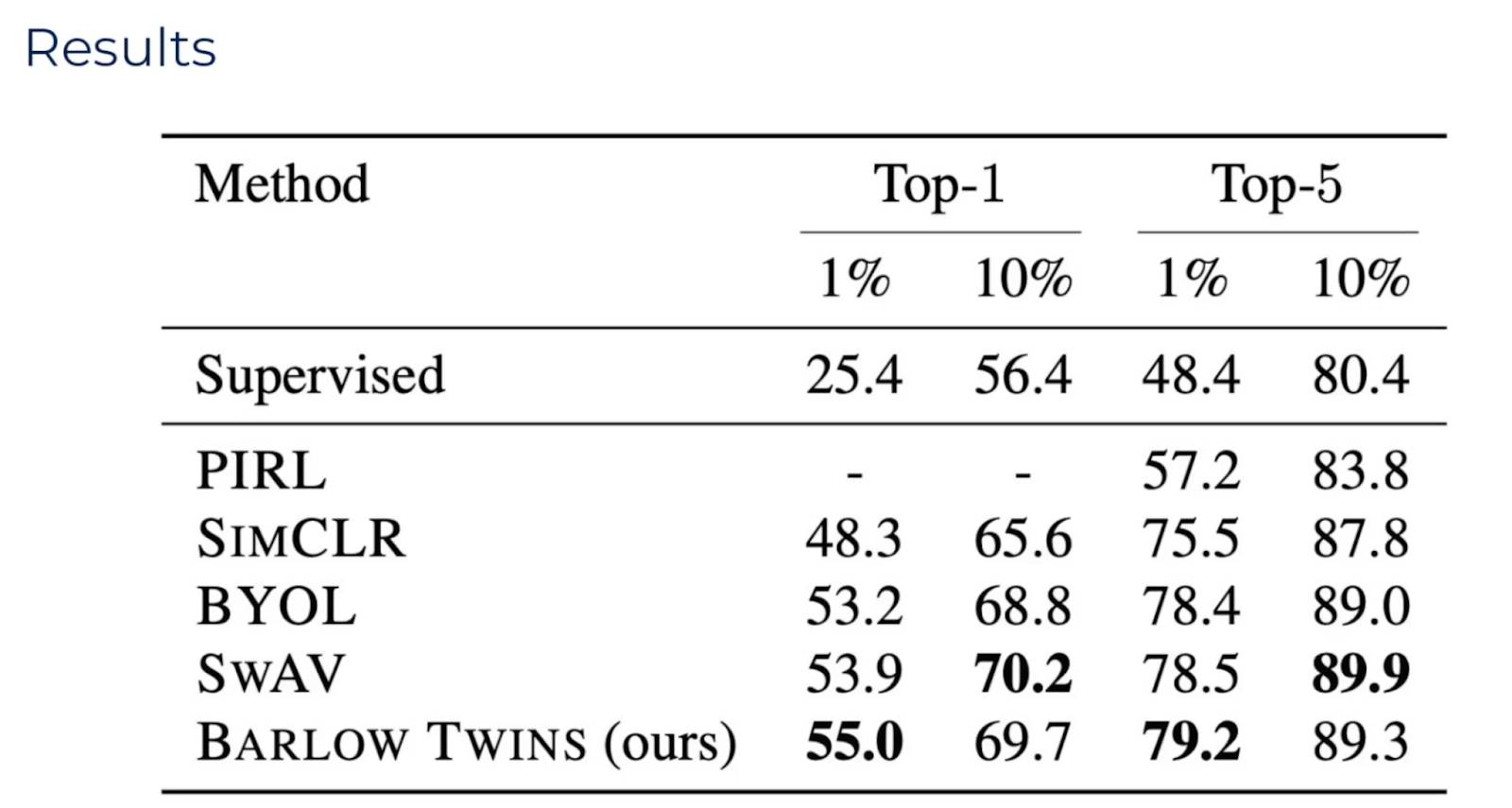
What if we train on 10% of the data? Well, using supervised learning, we get 56% accuracy and 70% accuracy for Barlow Twins.
Experimenting with SSL
I'm going to finish by talking about some of the experiments that I've done. One of the experiments in particular that’s really interesting was applying Barlow Twins to the fine-grained visual classification of an aircraft data set.
This is a really interesting data set because it's got 10,200 different images of 102 classes, where each class has 100 examples. Basically, it's photos of different aircraft types taken by photographers.

What's really interesting about this data set is that it’s fine-grained. So for example, we might have the Airbus A319, Airbus A320, and Airbus A321. These are all aircraft, they’re made in the same factory, and they're very similar in appearance. In fact, the only difference is the length of the aircraft. So this is particularly challenging when we're trying to train models to discriminate between these aircraft.
I'm going to start off by presenting the results, which I think are really interesting. The comparison I'm making is between a network that's been fully supervised on a data set and one that's undergone self-supervised pre-training.
In the graph below, you can see that I've done different experiments where I'm taking some proportion of these 10,200 images and I'm providing them to the supervised network to learn on.

In the case of the self-supervised pre-training, I'm giving them all access to all of the examples that are unlabeled, and then I'm fine-tuning the same number of examples that I provided to the fully supervised network.
The key here in this case, and the reason why self-supervised learning does so well, is that I'm using random initialization for the network.
When I talk about random initialization, what we’d normally do a lot of the time and in a lot of problems is we can use transfer learning. This is where we’d have a model that's been trained on something like ImageNet, and we’d take those weights and biases and transplant them, and then fine-tune or adjust them to a new situation.
But often what can happen is we can be in a situation where we have a very different data set, or we could have something where we've got a different number of channels so we can't really adapt the ImageNet data set. And that doesn't really help us. We need to use random initialization.
Now that you've seen where we got to, I want to talk about how we got there. What you can see below is after we trained Barlow Twins, I did a test. I mentioned before that our network takes in an image and generates a vector, and similar images semantically should generate similar vectors. And what I've done here is a k-nearest neighbor query.

With the image on the far left, I've looked for other images with similar output vectors to this image, and here immediately we can see something has gone wrong. What we were hoping for is a network capable of clustering similar aircraft types together.
We can see that it looks like the aircraft type has been matched correctly, but when we actually look at the images for a little bit, we realize that what we're matching on isn't the aircraft type, but rather the color in the image.
How do we get around this? A simple solution is to use augmentation to define invariances. What do I mean by this? Well, when the images undergo augmentation, essentially what we're doing is telling the network that image A and image B are semantically the same for that augmentation.
For example, if we get an aircraft and flip it left, or right, the network will see aircraft that turned to the left and aircraft that turned to the right, and they'll be told it’s the same aircraft. So this will ensure that we don't end up in a situation where it thinks that an aircraft pointed toward the left is semantically different from an aircraft pointed toward the right.
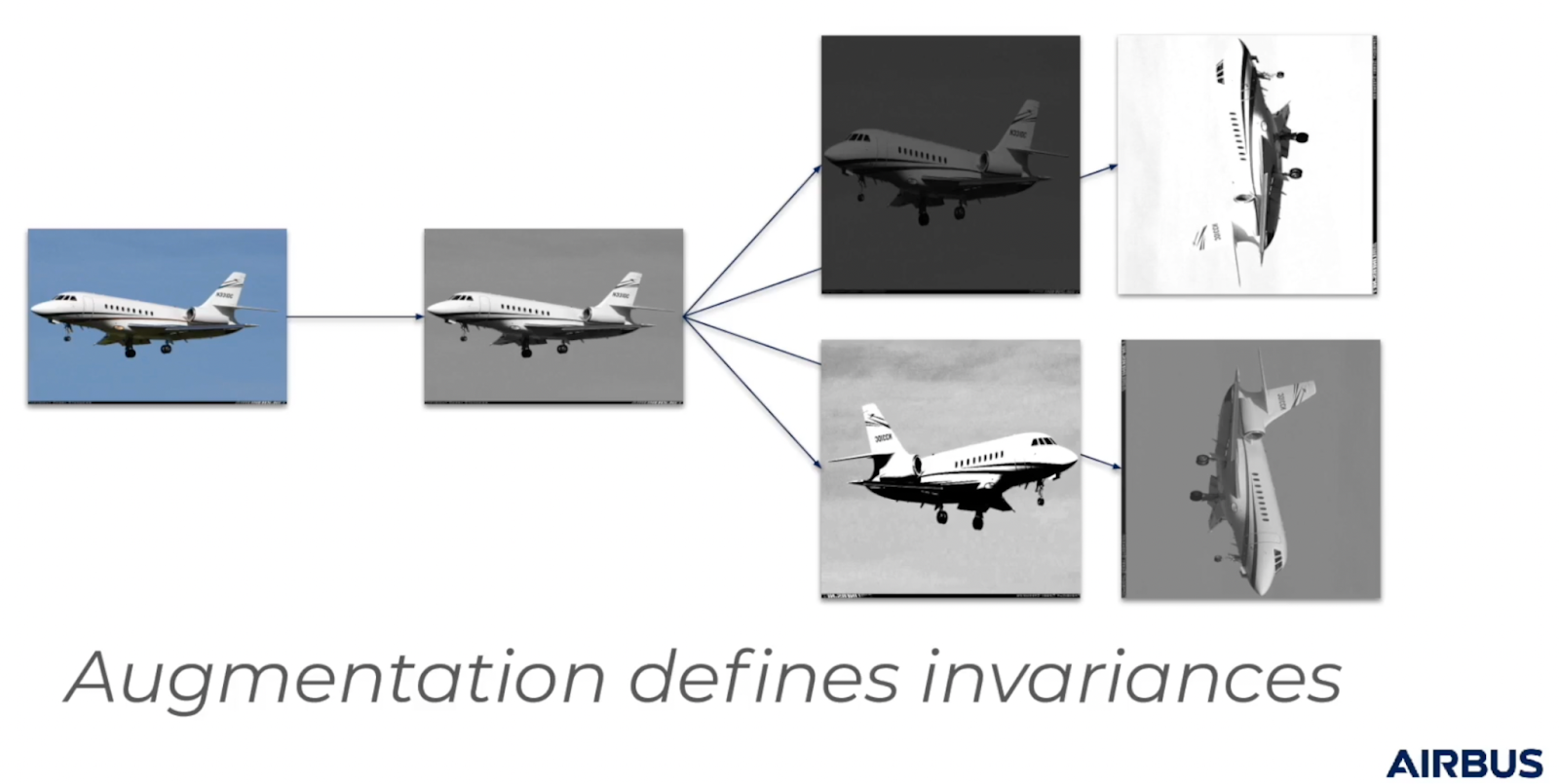
Another thing we can do is convert all of the images to grayscale. What this means is that it’ll lose any information about the color, and is no longer awarded for semantically clustering images according to their color.
Now, with this enhanced augmentation scheme, we get some really interesting results. If we look at the images below and look above them, we can actually see there's a class label.

What's particularly interesting here is that while 54 and eight are different classes, the aircraft that you can see there were designed by the same manufacturer.
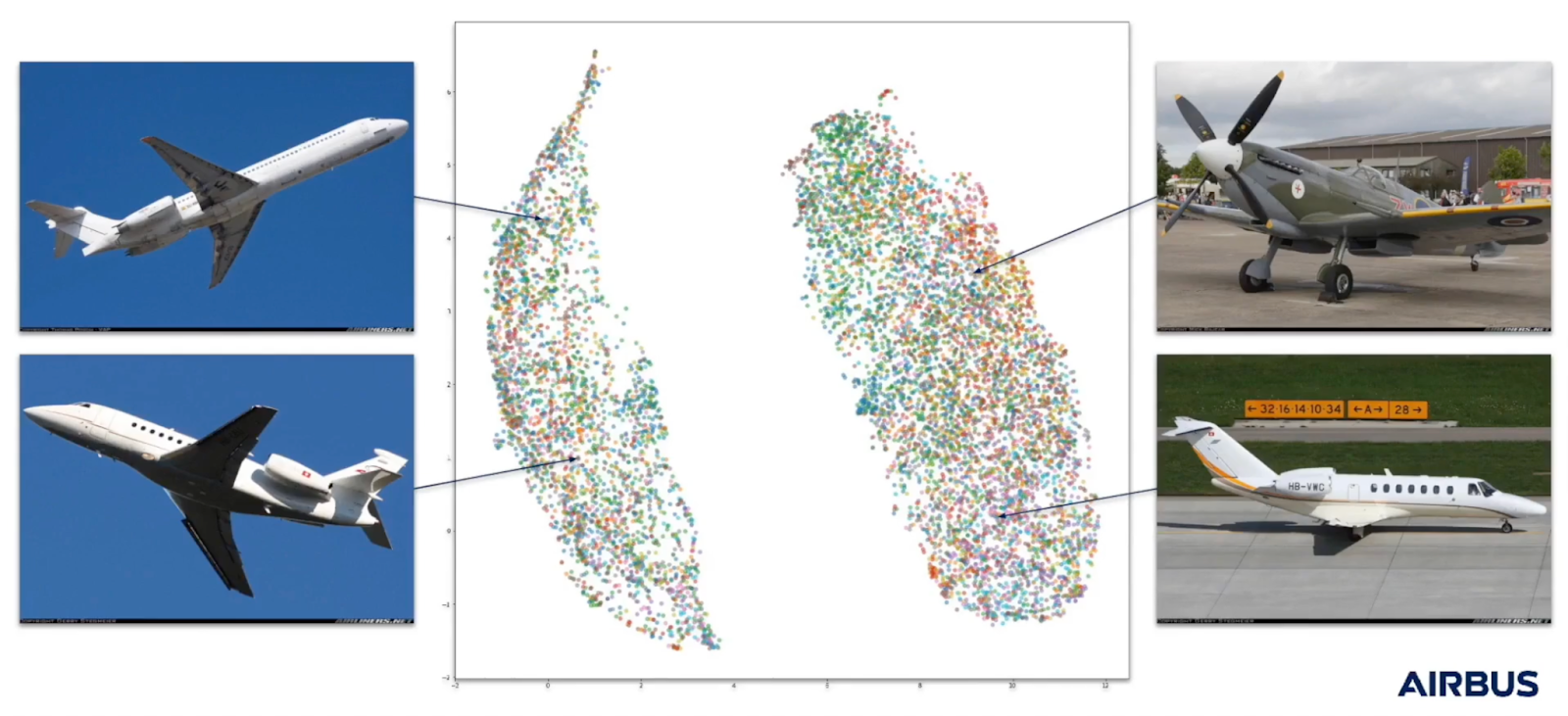
A really interesting representation has also been learned. If we take all of the vectors that have been generated, so 1,000-dimensional vectors, one per image, and then we use UMAP to bring that down from say, 1,000 dimensions to two-dimensional space, we can see there are two distinct clusters.
What's really interesting here is there's one cluster for aircraft that are flying, and another cluster for aircraft that are on the ground.
Where can SSL be used at Airbus?
Now, while experiments are interesting, I really want to talk about how we can use self-supervised learning at Airbus. I see a number of different opportunities that are really interesting. In particular, we've got the shop floor. This is where we're installing cameras into our final assembly lines to digitize what's happening.
The challenge here is that we can collect huge volumes of data, but it's very difficult to label all of it. So self-supervised learning gives us the opportunity to develop better models that can leverage these huge volumes of data that we've collected.
Other areas of interest include quality, because often when we're assessing quality use cases, we're also collecting huge volumes of data.
There are other areas like airline operations. So this would be offering new concepts and services to airlines to improve aircraft term performance, on-time performance, and things like that. There are huge volumes of data we collect as part of aircraft flight test campaigns.
And finally documentation. This is where we have millions of documents that have been generated over the past 50 years at the company and they've been digitized, but it's very hard to leverage them because they've been digitized from an analogue format. So self-supervised learning provides the opportunity to convert them into a digital format more accurately.
So, if self-supervised learning is practical, how would it change our strategy? It would incentivize us to:
- Collect more data
- Retain more data
- Focus on our data and model management
In fact, it really helps us focus on the fact that many people talk about data being the new oil. But I think for a long time, that hasn't really been true in the sense that you haven't been able to transform this data into something useful. But self-supervised learning really gives us this opportunity now to leverage all the data we've collected, and that's why I think it's so exciting.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

