
Generative artificial intelligence is a subset of AI technologies that allow machines to produce new content — such as text, images, audio, and video — by learning patterns from existing data. Gen AI differs from traditional AI systems that simply analyze or categorize data. Instead, generative AI models can create original material resembling the data they were trained on.
As generative AI is increasingly used across multiple industries, many companies are feeling its impact and benefits. According to our Generative AI report, text applications are at the top of the reasons for the adoption of generative AI tools (40.8%).
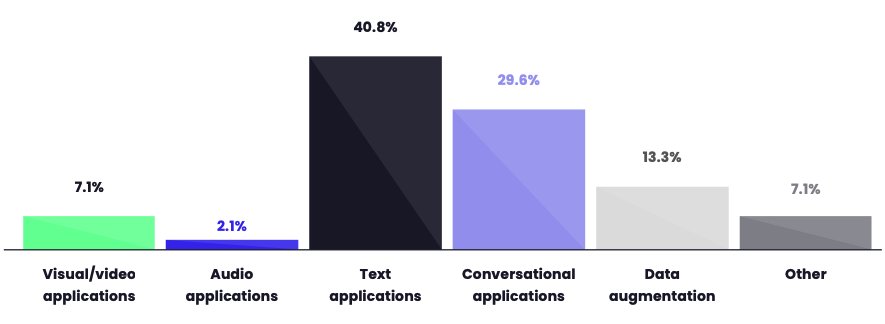
In an effort to understand how businesses are leveraging this technology more broadly, this article explores the main applications on Gen AI in detail. These are:
- Audio applications: AI systems can compose music in diverse styles or generate human-like speech, enhancing applications in entertainment and communication.
- Text applications: Models like ChatGPT can compose essays, articles, and poetry, and assist in drafting emails.
- Conversational applications: Fine-tuned chatbots can facilitate real-time conversational agents.
- Data augmentation: Tools can identify patterns, automate insights, and fill gaps in incomplete datasets to improve model training and decision-making.
- Video/visual applications: Tools, like DALL·E, Midjourney, and Sora transform textual descriptions into visual art, enabling rapid prototyping in design and entertainment.
Audio applications on gen AI
Generative AI audio models use machine learning techniques, artificial intelligence, and algorithms to create new sounds from existing data. This data can include musical scores, environmental sounds, audio recordings, or speech-to-sound effects.
After the models are trained, they can create new audio that’s original and unique. Each model uses different types of prompts to generate audio content, which can be:
- Environmental data
- MIDI data
- User input in real-time
- Text prompts
- Existing audio recordings
There are several applications of generative AI audio models:
1. Data sonification
Models can convert complex data patterns into auditory representations, which lets analysts and researchers understand and explore data through sound. This can be applied to scientific research, data visualization, and exploratory data analysis.
2. Interactive audio experiences
Creating interactive and dynamic audio experiences, models can generate adaptive soundtracks for virtual reality environments and video games. The models can also respond to environmental changes or user inputs to improve engagement and immersion.
3. Music generation and composition
Creating musical accompaniment or composing original music pieces is easy for these models; they can learn styles and patterns from existing compositions to generate rhythms, melodies, and harmonies.
4. Audio enhancement and restoration
You can restore and enhance audio recordings with generative AI, which lets you reduce noise, improve the overall quality of sound, and remove artifacts. This is useful in audio restoration for archival purposes.
5. Sound effects creation and synthesis
Models can enable the synthesis of unique and realistic sounds, like instruments, abstract soundscapes, and environmental effects. They can create sounds that copy real-world audio or completely new audio experiences.
6. Audio captioning and transcription
Helping to automate speech-to-text transcription and audio captioning, models can greatly improve accessibility in several media formats like podcasts, videos, and even live events.
7. Speech synthesis and voice cloning
You can clone someone’s voice through generative AI models and create speech that sounds exactly like them. This can be useful for audiobook narration, voice assistants, and voice-over production.
8. Personalized audio content
Through the use of generative AI models, you can create personalized audio content tailored to individual preferences. This can range from ambient soundscapes to personalized playlists or even AI-generated podcasts.
How do generative AI audio models work?
Like other AI systems, generative audio models train on vast data sets to generate fresh audio outputs. The specific training method can differ based on the architecture of each model.
Let's take a look at how this is generally done by exploring two distinct models: WaveNet and GANs.
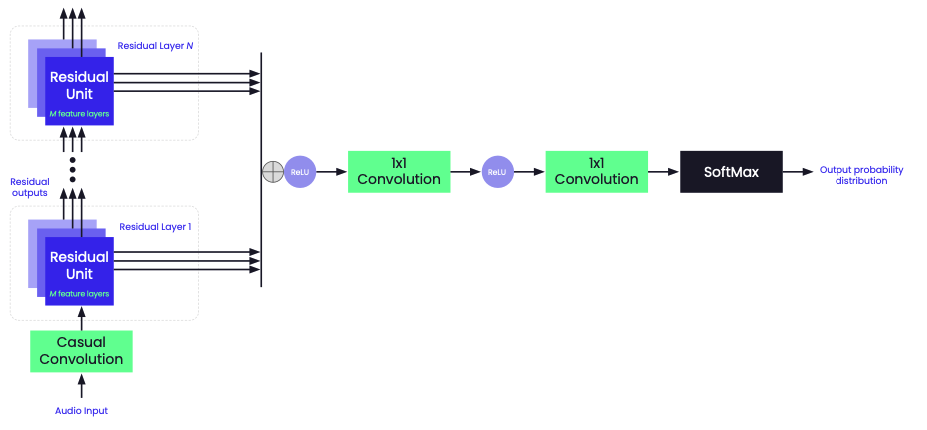
WaveNet
Created by Google DeepMind, WaveNet is a generative audio model grounded on deep neural networks. Using dilated convolutions, it creates great-quality audio by referencing previous audio samples. It can produce lifelike speech and music, finding applications in speech synthesis, audio enhancement, and audio style adaptation. Its operational flow consists of:
- Waveform sampling. WaveNet starts with an input waveform, usually a sequence of audio samples, processed through multiple convolutional layers.
- Dilated convolution. To recognize long-spanning dependencies in audio waveforms, WaveNet employs dilated convolutional layers. The dilation magnitude sets the receptive field's size in the convolutional layer, helping the model distinguish extended patterns.
- Autoregressive model. Functioning autoregressively, WaveNet sequentially generates audio samples, each influenced by its predecessors. It then forecasts the likelihood of the upcoming sample based on prior ones.
- Sampling mechanism. To draw audio samples from the model's predicted probability distribution, WaveNet adopts a softmax sampling approach, ensuring varied and realistic audio output.
- Training protocol. The model undergoes training using a maximum possibility estimation technique, which is designed to increase the training data's probability when it comes to the model's parameters.
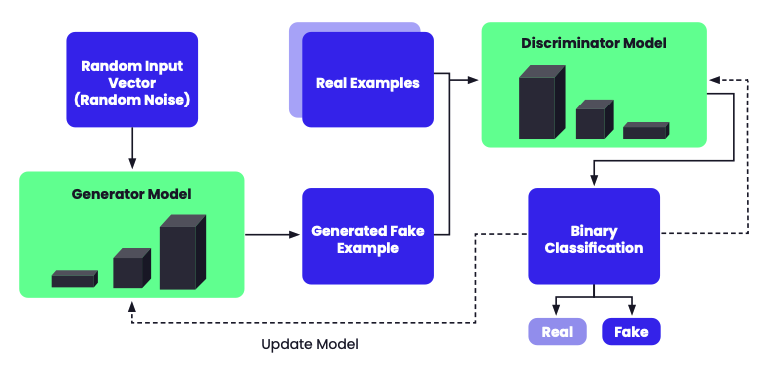
Generative Adversarial Networks (GANs)
A GAN encompasses two neural networks: a generator for creating audio samples and a discriminator for judging their authenticity. Here's an overview:
- Architecture. GANs are structured with a generator and discriminator. The former ingests a random noise vector, outputting an audio sample, while the latter evaluates the audio's authenticity.
- Training dynamics. The generator creates audio samples from random noise during training and the discriminator's task is to categorize them. Working together, the generator refines its output to appear genuine to the discriminator, and this synchronization is executed by reducing the binary cross-entropy loss between the discriminator's findings and the actual labels of each sample.
- Adversarial loss. GANs aim to reduce the adversarial loss, which is the gap between real audio sample distributions and fake ones. This minimization rotates between the generator's enhancements for more authentic output and the discriminator's improvements in differentiating real from generated audio.
- Audio applications. GANs have various audio purposes, such as music creation, audio style modulation, and audio rectification. For music creation, the generator refines itself to form new musical outputs. For style modulation, it adapts the style from one sample to another. For rectification, it's trained to eliminate noise or imperfections.
Generative AI text applications
Artificial intelligence text generators use AI to create written copy, which can be helpful for applications like website content creation, report and article generation, social media post creation, and more.
By using existing data, these artificial intelligence text generators can make sure that content fits tailored interests. They also help with providing recommendations on what someone will most be interested in, from products to information.

There are several applications of generative AI text models:
1. Language translation
These models can be used to improve language translation services, as they can analyze large volumes of text and generate accurate translations in real time. This helps to enhance communication across different languages.
2. Content creation
Perhaps one of the most popular applications, content creation refers to blog posts, social media posts, product descriptions, and more. Models are trained on large amounts of data and can produce high-quality content very quickly.
3. Summarization
Helpful for text summarization, models provide concise and easy-to-read versions of information by highlighting the most important points. This is useful when it comes to summarizing research papers, books, blog posts, and other long-form content.
4. Chatbot and virtual assistants
Both virtual assistants and chatbots use text generation models to interact with users in a conversational way. These assistants can understand user queries and offer relevant answers, alongside providing personalized information and assistance.
5. SEO content
Text generators can help to optimize text for search engines. They can decide on the meta description, headline, and even keywords. You can easily find out the most search topics and their keyword volumes to make sure you have the best-ranking URLs.

How do generative AI text models work?
AI-driven content generators use natural language processing (NLP) and natural language generation (NLG) techniques to create text. These tools offer the advantage of improving enterprise data, tailoring content based on user interactions, and crafting individualized product descriptions.
Algorithmic structure and training
Content-based on NLG is crafted and structured by algorithms. These are typically text-generation algorithms that undergo an initial phase of unsupervised learning. During this phase, a language transformer model immerses itself in vast datasets, extracting a variety of insights.
By training on extensive data, the model becomes skilled in creating precise vector representations. This helps in predicting words, phrases, and larger textual blocks with heightened context awareness.
Evolution from RNNs to transformers
While Recurrent Neural Networks (RNNs) have been a traditional choice for deep learning, they often have difficulty in modeling extended contexts. This shortcoming comes from the vanishing gradient problem.
This issue happens when deep networks, either feed-forward or recurrent, find it difficult to relay information from the output layers back to the initial layers. This leads to multi-layered models either failing to train efficiently on specific datasets or settling prematurely for less-than-ideal solutions.
Transformers emerged as a solution to this dilemma. With the increase in data volume and architectural complexity, transformers provide advantages like parallel processing capabilities. They’re experienced at recognizing long patterns, which leads to stronger and more nuanced language models.
Simplified, the steps to text generation look like this:
- Data collection and pre-processing. Text data gathering, cleaning, and tokenization into smaller units for model inputs.
- Model training. The model is trained on token sequences, and it adjusts its parameters in order to predict the next token in a sequence according to the previous ones.
- Generation. After the model is trained, it can create new text by predicting one token at a time based on the provided seed sequence and on tokens that were previously generated.
- Decoding strategies. You can use different strategies, such as beam search, op-k/top-p sampling, or greedy coding to choose the next token.
- Fine-tuning. The pre-trained models are regularly adjusted on particular tasks or domains to improve performance.
Conversational applications
Conversational AI focuses on helping the natural language conversations between humans and AI systems. Leveraging technology like NLG and Natural Language Understanding (NLU), it allows for seamless interactions.
There are several applications of generative AI conversational models:
1. Natural Language Understanding (NLU)
Conversational AI uses sophisticated NLU techniques to understand and interpret the meanings behind user statements and queries. Through analyzing intent, context, and entities in user inputs, conversational AI can then extract important information to generate appropriate answers.
2. Speech recognition
Conversational AI systems use advanced algorithms to transform spoken language into text. This lets the systems understand and process user inputs in the form of voice or speech commands.
3. Natural language generation (NLG)
To generate human-like answers in real time, conversational AI systems use NLG techniques. By taking advantage of pre-defined templates, neural networks, or machine learning models, the systems can create meaningful and contextually appropriate answers to queries.
4. Dialogue management
Using strong dialogue management algorithms, conversational AI systems can maintain a context-aware and coherent conversation. The algorithms allow AI systems to understand and answer user inputs in a natural and human-like way.
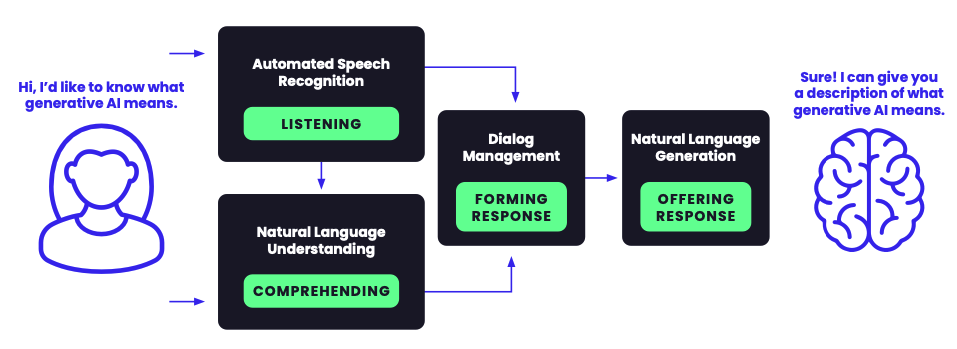
How do generative AI conversational models work?
Backed by underlying deep neural networks and machine learning, a typical conversational AI flow involves:
- An interface that lets users input text into the system or automatic speech recognition, which is a user interface that transforms speech into text.
- Natural language processing extracts users’ intent from text or audio input, translating text into structured data.
- Natural language understanding processes data based on context, grammar, and meaning to better understand entity and intent. It also helps it to act as a dialogue management unit in order to build appropriate answers.
- An AI model predicts the best answer for users according to the intent and the models’ training data. Natural language generation infers from the processes above to form an appropriate answer to interact with humans.
The role of gen AI data augmentation
Through using artificial intelligence algorithms, especially generative models, you can create new, synthetic data points that can be added to an already existing dataset. This is typically used in machine learning and deep learning applications to enhance model performance, achieved by increasing both the size and the diversity of the training data.
Data augmentation can help to overcome challenges of imbalance or limited datasets. By creating new data points similar to the original data, data scientists can make sure that models are stronger and better at generalizing unseen data.
Generative AI models like Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) are promising for the generation of high-quality synthetic data. They learn the underlying distribution of input data and are able to create new samples that very closely resemble original data points
Variational Autoencoders (VAEs)
Type of generative model that utilizes an encoder-decoder architecture. The encoder learns a lower-dimensional representation (latent space) of the input data and the decoder rebuilds the input data from the latent space.
VAEs force a probabilistic structure on the latent space that lets them create new data points by sampling from learned distribution. These models are useful for data augmentation tasks with input data that has a complex structure, like text or images.
Generative Adversarial Networks (GANs)
Consisting of two neural networks, a discriminator and a generator, that are simultaneously trained. The generator creates synthetic data points and the discriminator assesses the quality of the created data by comparing it to the original data.
Both the generator and the discriminator compete against each other, with the generator attempting to create realistic data points to deceive the discriminator. The discriminator tries to accurately tell apart real and generated data, and as the training progresses, the generator gets better at producing high-quality synthetic data.
There are several applications of generative AI data augmentation models:
1. Medical imaging
The generation of synthetic medical imaging like MRI scans or X-rays helps to increase the size of training datasets and enhance diagnostic model performance.
2. Natural language processing (NLP)
Creating new text samples by changing existing sentences, like replacing words with synonyms, adding noise, or changing word order. This can help enhance the performance of machine translation models, text classification, and sentiment analysis.
3. Computer vision
The enhancement of image datasets by creating new images with different transformations, like translations, rotations, and scaling. Can help to enhance the performance of object detection, image classification, and segmentation models.
4. Time series analysis
Generating synthetic time series data by modeling underlying patterns and creating new sequences with similar characteristics, which can help enhance the performance of anomaly detection, time series forecasting, and classification models.
5. Autonomous systems
Creating synthetic sensor data for autonomous vehicles and drones allows the safe and extensive training of artificial intelligence systems without including real-world risks.
6. Robotics
Generating both synthetic objects and scenes lets robots be trained for tasks like navigation and manipulation in virtual environments before they’re deployed into the real world.
How do generative AI data augmentation models work?
Augmented data derives from original data with minor changes and synthetic data is artificially generated without using the original dataset. The latter often uses GANs and deep neural networks (DNNs) in order to generate synthetic data.
There are a few data augmentation techniques:
Text data augmentation
- Sentence or word shuffling. Change the position of a sentence or word randomly.
- Word replacement. You can replace words with synonyms.
- Syntax-tree manipulation. Paraphrase the sentence by using the same word.
- Random word insertion. Add words at random.
- Random word deletion. Remove words at random.
Audio data augmentation
- Noise injection. Add random or Gaussian noise to audio datasets to enhance model performance.
- Shifting. Shift the audio left or right with random seconds.
- Changing speed. Stretches the times series by a fixed rate.
- Changing pitch. Change the audio pitch randomly.
Image data augmentation
- Color space transformations. Change the RGB color channels, brightness, and contrast randomly.
- Image mixing. Blend and mix multiple images.
- Geometric transformations. Crop, zoom, flip, rotate, and stretch images randomly; however, be careful when applying various transformations on the same images, as it can reduce the model’s performance.
- Random erasing. Remove part of the original image.
- Kernel filters. Change the blurring or sharpness of the image randomly.
Visual/video applications
Generative AI is becoming increasingly important for video applications due to its ability to produce, modify, and analyze video content in ways that were previously impractical or impossible, making it a key tool for AI video solutions. It also integrates seamlessly with tools like an audio editor and AI voice cloning to enhance the overall production process.
With the growing use of generative AI for video applications, however, some ethical concerns arise. Deep Fakes, for example, have been used in malicious ways, and there's a growing need for tools to detect and counteract them.
Authenticity verification, informed consent for using someone's likeness, and potential impacts on jobs in the video production industry are just some of the challenges that still need to be navigated.
There are several applications of generative AI video models:
1. Content creation
Generative models can be used to create original video content, such as animations, visual effects, or entire scenes. This is especially important for filmmakers or advertisers on a tight budget who might not be able to afford extensive CGI or live-action shoots.
2. Video enhancement
Generative models can upscale low-resolution videos to higher resolutions, fill in missing frames to smooth out videos, or restore old or damaged video footage.
3. Personalized content
Generative AI can change videos to fit individual preferences or requirements. For example, a scene could be adjusted to show a viewer's name on a signboard, or a product that the viewer had previously expressed interest in.
4. Virtual reality and gaming
Generative AI can be used to generate realistic, interactive environments or characters. This offers the potential for more dynamic and responsive worlds in games or virtual reality experiences.
5. Training
Due to its ability to create diverse and realistic scenarios, generative AI is great for training purposes. It can generate various road scenarios for driver training or medical scenarios for training healthcare professionals.
6. Data augmentation
For video-based machine learning projects, sometimes there isn't enough data. Generative models can create additional video data that's similar but not identical to the existing dataset, which enhances the robustness of the trained models.
7. Video compression
Generative models can help in executing more efficient video compression techniques by learning to reproduce high-quality videos from compressed representations.
8. Interactive content
Generative models can be used in interactive video installations or experiences, where the video content responds to user inputs in real time.
9. Marketing and advertising
Companies can use generative AI to create personalized video ads for viewers or to quickly generate multiple versions of a video advertisement for A/B testing.
10. Video synthesis from other inputs
Generative AI can produce video clips from textual descriptions or other types of inputs, allowing for new ways of storytelling or visualization techniques.
How do generative AI video models work?
Generative video models are computer programs that create new videos based on existing ones. They learn from video collections and generate new videos that look both unique and realistic.
With practical applications in virtual reality, film, and video game development, generative video models can be used for content creation, video synthesis, and special effects generation.
Creating a generative video model involves:
Preparing video data
The first step includes gathering a varied set of videos reflecting the kind of output to produce. Streamlining and refining this collection by discarding any unrelated or subpar content guarantees both quality and relevancy. The data must then be organized into separate sets for training and validating the model's performance.
Choosing the right generative model
Picking an appropriate architecture for generating videos is vital. Potential choices include Variational Autoencoders (VAEs) or Generative Adversarial Networks (GANs). The options are:
- Variational Autoencoders (VAEs). These models acquire a latent understanding of videos and then craft new sequences by pulling samples from this acquired latent domain.
- Generative Adversarial Networks (GANs). These models consist of a generator and discriminator that work in tandem to produce lifelike videos.
- Recurrent Neural Networks (RNNs). Models adept at recognizing time-based patterns in videos, producing sequences grounded in these identified patterns.
- Conditional generative models. These models create videos based on specific given attributes or data. Factors like computational needs, intricacy, and project-specific demands need to be taken into account when selecting.
Training process for the video generation model
The structure and hyperparameters for the selected generative model are outlined. The curated video data teaches the model, aiming to create both believable and varied video sequences. The model's efficacy needs to be checked consistently using the validation dataset.
Refining the output
If needed, the generated sequences need to be adjusted to uplift their clarity and continuity. Employ various enhancement techniques, such as diminishing noise, stabilizing the video, or adjusting colors.
Assessment and optimization of the model
The produced videos need to be examined by using multiple criteria, like their visual appeal, authenticity, and variety. Opinions from specialized users or experts can be helpful in gauging the utility and efficiency of the video-generating model.
Putting the model to use
If everything is working as it should, the model can be launched to produce new video sequences. The video generation model can be utilized in diverse areas, including video creation, special cinematic effects, or immersive experiences in virtual reality.
Curious to see the full report? Download it below!


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

