
My name is Ananth Ranganathan and I work in Computer Vision (Oculus) at Facebook. Oculus Insight is the "inside-out" positional tracking system that enables full 6DoF (degree of freedom) tracking on these VR headsets, as well as full 6D0F controller tracking for these headsets.
In this article, I’ll explain the technology behind the system which is based on cameras and an IMU mounted on the headsets. I’ll also describe how they tuned the system to get millimeter-level precision needed for a smooth VR experience, as well as the testing and validation required to get it robustly working in varied environments.
Here are our main talking points:
- What is a VR headset?
- ‘Outside in’ vs. ‘Inside out’ VR
- SLAM Computer vision method
- Building a map and localizing
- Making the map consistent
- Oculus Insight: Visual-inertial SLAM on Quest
Let’s go ahead and dive in 👇
What is a VR headset?

A user in a headset will be able to see VR content. To create a good VR experience for your users you need the content to be rendered really well and the motions you make in the real world have to be accurately reflected in VR. Both the headset and VR controllers have to be well-matched in the motions the user is making and they have to be transferred to virtual reality.
The brain uses about 40% of its processing for visual processing, meaning the visual cortex is about 40% of our brain. We are trying to fool that part of your brain by making VR appear to be like the real world which is a pretty big task with many pieces to it. The piece I’m going to focus on in this article is about pose tracking, meaning how we transfer the motions you’re making in the real world over to virtual reality.
We need to keep in mind that because we are trying to fool the brain, the pose tracking needs to be really high fidelity and accurate.
‘Outside in’ vs. ‘Inside out’ VR
‘Outside in’ VR
Our first product, the Oculus Rift is a class of VR headsets called ‘outside in’ VR. On the left, there are cameras positioned externally looking at the headset and that's how the headset is tracked. The cameras are outside but are looking in, hence it's called ‘outside in’ VR.
For this class of headsets, you need the cameras and the headsets to be attached to a computer. All the processing takes place on a computer, which is usually a high-end gaming machine with a GPU. There’s no processing on the VR headset, there are static cameras looking at the headset and that's how the headset gets tracked. There are very few restrictions on content complexity because you have this high-end gaming machine so you can render really complex games.
Standalone or ‘Inside out’ VR
We launched the Oculus Quest last year which is a standalone VR, also what is called ‘Inside out’ VR. There are cameras on the headset looking out into the world but there's nothing looking in. In fact, the cameras are in and it's looking out, hence ‘inside out’.
There's a mobile processor, everything is self-contained on the headset. There are no cables and accessories so you have a lot more freedom to move around in VR, which enriches the VR experience. Since all the compute is on the headset, we are also constrained on what sort of content we can render and we have to be really efficient.
There are some requirements for a mobile processor:
- Low latency: The motion you're making in the real world has to be immediately reflected in VR. This is something humans are really sensitive to.
- Perceptual quality: You need submillimeter accuracy in terms of tracking.
- Robustness: It needs to be robust to a wide range of environments and to work in everyone's homes with all different types of lighting and conditions.
- Power-efficient: If you want to play a game, it's no good if the headset runs out of power in 15 minutes so it needs to be power efficient and low on compute.
SLAM Computer vision method
For the pose tracking for ‘Inside out’ standalone cameras, the underlying computer vision method we use is called SLAM, which stands for Simultaneous Localization and Mapping. The name SLAM comes from the robotics community so I'll use a robotics analogy to explain it.
A probabilistic estimation problem
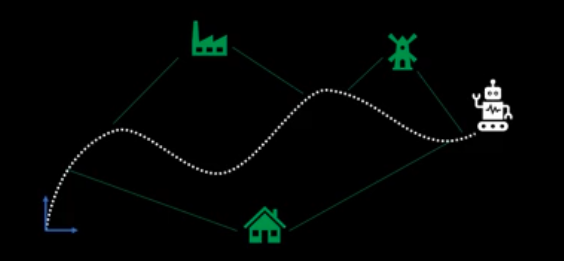
For example, there's a robot going around in the world. It needs to know where it is at any given point. Of course, there’s no absolute coordinate frame, we're not talking about GPS here. The position where the robot starts off is the origin of the coordinate frame. Then, the robot moves around and it needs to estimate its trajectory as it's moving. The way it does this is by looking at landmarks in the environment. If the robot is moving around the city, these landmarks could be factories or houses.
What SLAM is doing is the robot estimates the positions of the landmarks with respect to itself and then because it knows the landmarks aren't moving it's also estimating its own position with respect to the fixed landmarks. When we’re estimating the position of the landmarks, we are mapping the world. When we’re estimating our position, we are localizing against the map and we’re doing both simultaneously.

The way we are solving this is that the robot sees a particular landmark in one location, then it moves around and sees the same landmark from another location. It knows the landmark hasn't moved so it can estimate its own motion by solving an optimization problem based on knowing the landmark is fixed. What this means is we’re trying to minimize some error function or loss function that modifies both the landmark locations and the trajectory of the robot at the same time. This example above is using one landmark but in practice, you'd have hundreds of thousands of landmarks.
Sensors for SLAM in VR
On Oculus Quest, we have a couple of different types of sensors:
- Cameras: We have four cameras on the edges of the headset and these are all wide field of view fisheye lenses which means they cover a lot of the viewing sphere.
- IMU: This is an accelerometer and the gyroscope gives us accelerations and rotational velocities we can integrate to get position over a short period of time.
Building a map and localizing
What is the Quest doing when it's building a map and localizing? The landmarks are 3D points in the environment, which correspond to features in the images the Quest is seeing. Based on those 3D points, it's localizing its own position.

As the user moves around, the mapping part is building a point cloud and the localizing part is finding the position of the headset with respect to this point. This is what SLAM means in the context of Oculus Quest. Now that we know what the map looks like, this is what the features corresponding to those landmarks or 3D points look like in the image. Above is an image from a Quest camera, it's low resolution but it's a high field of view. The features we detect are corners, which are shown here as these white dots. These are the features used to find 3D points which are added to the map.
Adding points to the map: Matching & triangulation

Matching and triangulation is how we find depth by using stereo. As humans, we have two eyes and a baseline and that's what we use to find depth. Here, it’s the same process. Let’s use the duck above as an example. The features we use are corners. The reason why we use corners is that they’re very recognizable, so you can find the location of the corner in both x and y.
If you take a small window and move it across the image, as soon as you go away from the corner and do a delta or subtract these image patches, you'll see a lot of difference as opposed to a line feature. If you're moving along the line, you don't know where along the line you are, whereas, for a corner, this is pretty clear.
Tracking on the map
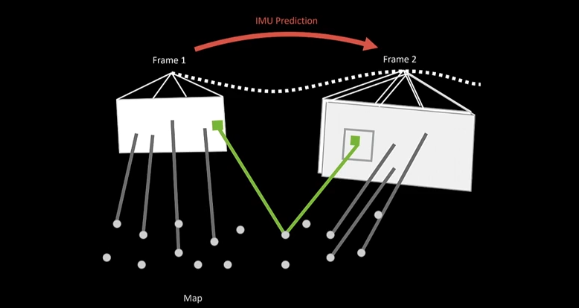
Once we detect a corner in one frame, we back project the ray along which the corner lies in 3D. The corner in the image corresponds to 3D points in the world. We project this 3D ray onto a second camera. This is stereo geometry and this red line you see in the image above is called an AP polar line.
Once you have a corner in one image, all you need to do to find it in the other image is to move along and search this AP polar line. Once you search this, you get a second corner. Since the cameras are calibrated, we know exactly where these cameras are on the Quest and the baseline between the two cameras so we can find the 3D location of the point using triangulation. Once we have the 3D location we added to the map, it becomes a landmark in the map and this is how we add points to the map.

Once we have the map, we'd have to do the localization part, which is also called tracking on a map because you're tracking your trajectory as you go. The way this works is by having a lot of points already in the map, projecting them into one frame and you get a second frame. Because we have an IMU we roughly know the motion that happened between frame one and frame two and we use that to find the location of some of these points in the second frame.
Finding the location of frame two is an optimization problem. If we wanted to add points to the map at every frame, it wouldn’t work out well because the compute required is too much and the map will become too dense. What we do instead is we don't add points to the map for every frame but we only do it infrequently. The frames we select to add points to the map are called keyframes so keyframing is a way to reduce compute and make this all viable.
Making the map consistent
Large scale optimization: Visual-inertial bundle adjustment

If you have a long trajectory or a large map, you need to make it sort of globally consistent. The way we do this is called ‘bundle adjustment’ in computer vision or robotics terminology. For example, here you have two keyframes viewing a point in the map. What we do is project this point into both the keyframes assuming there’s some error in the 3D location of the point so that it's not projected exactly in the right place and our corner detection also has some error. This is called ‘reprojection error’.
There's also an IMU integration term, which is also not precise. There are kind of two error functions here, we combine them, get a combined loss function, and we can minimize that over a huge map. Once we do this bundle adjustment process, the map is globally consistent.
Oculus Insight: Visual-inertial SLAM on Quest

The main takeaway here is that the way we make this viable on a mobile processor is by doing two main things. One is by multi-threading, so there's an IMU thread and there's a camera thread, which is called the tracker thread here. The IMU is typically running at 500 hertz, or one kilohertz so this thread is really cycling through a lot and it has to keep up with the IMU rate. If your IMU is one kilohertz, this thread cannot take more than one millisecond per iteration. The amount of work we can do here is very little. The only thing we do is integrate the IMU to get pose over a small interval.
The tracker thread is running off the cameras. It has to run a camera frame rate, on the Quest, this is 30 frames per second. It’s actually a mapper thread doing the keyframing and adding points to the map which runs at a much slower rate. This is very compute-intensive because it's also doing the bundle adjustment, which is a large optimization problem.
To make this efficient we are using hardware acceleration so we have a DSP to do all the image processing parts. The image processing we are using is building an image pyramid, detecting corners, doing the matching, and all of these lower-level things we can speed up using the DSP.
Now we have an efficient pipeline working reasonably well but we also need to do some additional things to make sure this translates into a good VR user experience. However, the challenges are:
- Efficiency
- Robustness: Meaning it has to work in many different types of environments.
- Benchmarking & Metrics: This is the way we get robustness and we can rely on this to know how the system is performing.
- Perceptual experience
Motion to photon latency

We discussed efficiency in the pose estimation or the slam part but that's actually not the full story as far as VR latency is concerned. If we were not using the IMU and just using cameras, we would need two camera frames to estimate pose. On Quest, the camera runs at 30 frames per second. If you had no IMU you would have to wait 60 milliseconds to even get a pose but we have an IMU and it allows us to predict the pose of the headset at the time that we complete frame processing. So suddenly, instead of being 60 milliseconds in the past, you are right at the present and no lag but that's still not the full story because we still want to render content and the content rendering also takes time.
When you as a user do a motion and see the motion reflected in VR, what you're seeing is actually an extrapolated pose because the rendering takes some time. So the time between when the camera frame is read off the sensor, and the time when you see the actual content being rendered is what is called ‘motion to photon latency’. This is what we try to minimize for a VR headset.
Controller tracking

On the controllers, we have IR LEDs that are calibrated to know the locations and we also have a controller IMU similar to what we have on the headset. What is happening is that the cameras on the Quest are also tracking the IR LEDs on the controllers and since we know the relative distance between the LEDs on the controller, we know the pose of the controller with respect to the headset. This is similar to a camera checkerboard calibration problem.
Since the headset cameras have a wide field of view, you can move your controllers anywhere and they still get tracked. Everything in the background is darkened out so it only sees the infrared LEDs.
🔮 What’s next?
Our goal at Facebook is to move towards augmented reality (AR). So far, we have worked on VR and shipped VR headsets but we’re working towards augmented reality in the longer term. To get there, we need to do a lot more work and we need shared experiences.
Virtual reality is an isolating experience, when you put on the headset you don't see anything or anyone. For AR, we need to work on shared experiences and on semantics in the world. Right now we have this point cloud but we don't know the objects, the planes, or the surfaces that are there so we need to add a lot more semantics to the world as the system sees it.
We need to expand this to be world-scale what is currently a room-scale device. The mapping cannot scale to a building for instance because the compute doesn't hold up for a mobile platform.
We need to make this distributed and world scale and we also need to make the map remain fresh at all times because the world is changing and the map we’re building needs to change along with it. This is what we call lifelong mapping.
At Facebook, we have a saying that the journey is only 1% complete and the work we're doing, it's literally true.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

