
Hi, my name is Lakshmi Krishnan. I'm a team lead in the software applications group at Graphcore. In this article, I'm going to talk about how we helped scale the training of computer vision models on the IPU.
Main topics
- Supporting scalable machine intelligence systems
- IPU hardware
- Poplar software stack
- PopTorch code walkthrough
- Poplar SDK features
But first, let me give a bit of background on Graphcore:
What we do

Graphcore develops processes and compute systems specifically designed for AI and machine learning workloads. We provide hardware technology such as the IPU processor, software such as Poplar, as well as development tools. This is all part of a complete solution to enable innovators to solve current and future ML problems.
We've launched our first generation of PCIe card-based products, which were delivered via IPU service. We have now announced our MK2 processor, delivered in the IPU-M2000 product, which can really ramp up into 10s of 1000s of systems for supercomputing scale up.
Supporting scalable Machine intelligence systems

At Graphcore, we have co-designed and tightly coupled hardware and software systems for scalable machine intelligence workloads. Ease of use is at the core of our design philosophy. In this article, I'm going to show you how the proper SDK, comprised of common machine learning frameworks, and popular programming interface, allows practitioners to easily scale computer vision models.
Now, I’m going to outline the features of our IPU hardware. This allows us to scale the training of computer vision models on a large number of IPU devices.
IPU hardware
The IPU is a massively powerful distributed processing engine.
MK2 IPU Processor
Recently, we've introduced a second-generation IPU. The MK2 processor, built with 59.4 billion transistors, consists of 1,472 independent IPU tiles or processor cores. Each one is capable of executing six independent workers in parallel for a total of 8,832 fully independent program threads.
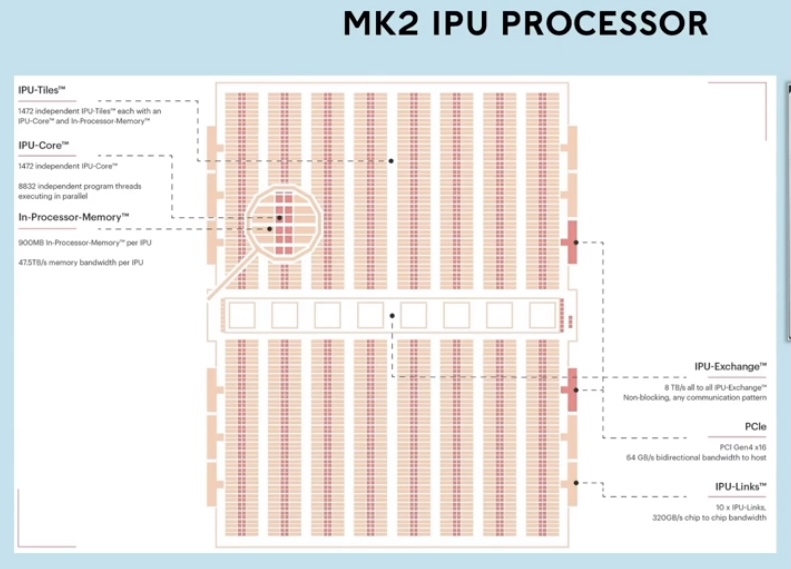
It utilizes 47.5 terabytes per second of memory bandwidth, with each IPU having access to 900 megabytes of on-chip memory. To support fast distributed compute on-chip, we have eight terabytes per second total communication bandwidth, with fully deterministic execution, driven by compiler support and software.
Hardware-accelerated tile synchronization allows low latency messaging of work completion between the tiles. This allows the processor to move between compute and exchange phases.
Scaling across devices
Scaling across devices allows us to support model and data-parallel machine learning applications.

The IPU exchange model
This extends off the device to support software-driven cross IPU synchronization. This great technology allows chip-to-chip communication at massive scale. It allows tile messaging across IPU devices and supports optimized cross-IPU synchronization.
The GCD
This is the graph control domain for applications. It creates a single large IPU target from applications for supporting both data-parallel and modern parallel training configurations.
The IPU-Link
This supports communication between IPUs. The layout is fully software configurable, and it supports point-to-point tile messaging.
Scaling across systems
Along with scaling across IPU devices, we also support scaling across systems. This allows us to build very large machine intelligence applications on the IPUs. Here you can see how we can create a 256 IPU application target from 464 IPU domains. 👇
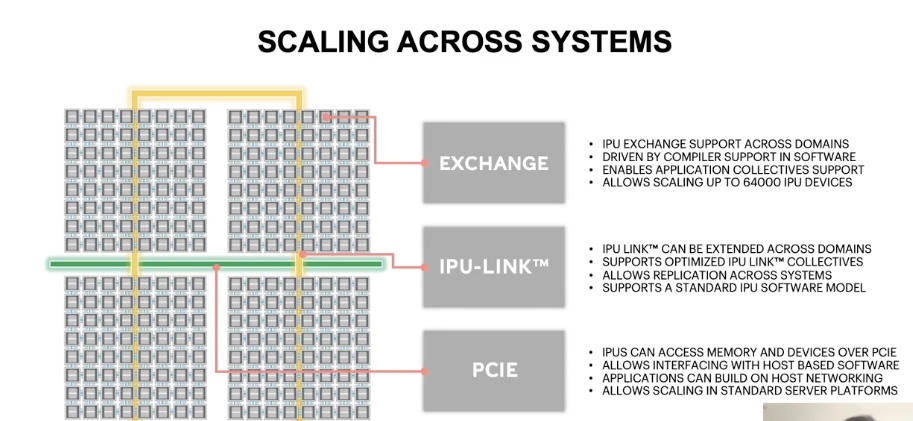
Common IPU software parameters support scaling across devices and across systems. We use the exchange parameters and IPU-LINK, along with host connectivity over PCIe Express, to build massively parallel applications.
Scaling at rack-scale
Recently, we've introduced a second-generation IPU pod platform, which allows us to scale at the rack level. They utilize both in-processor and streaming exchange memory and are equipped with optimized communication collectives via the IPU fabric.
Disaggregated hardware systems can be reconfigured to allow flexible application domain targets for machine learning frameworks.
Think of an IPU machine as a building block for scalable AI systems. Each IPU machine consists of four Colossus MK2 processes, offering one Petaflops per second of AI compute, with access to integrated streaming memory. It's fully integrated as a target for machine learning frameworks in our Poplar SDK.

IPU Scaleout: innovations & Differentiators
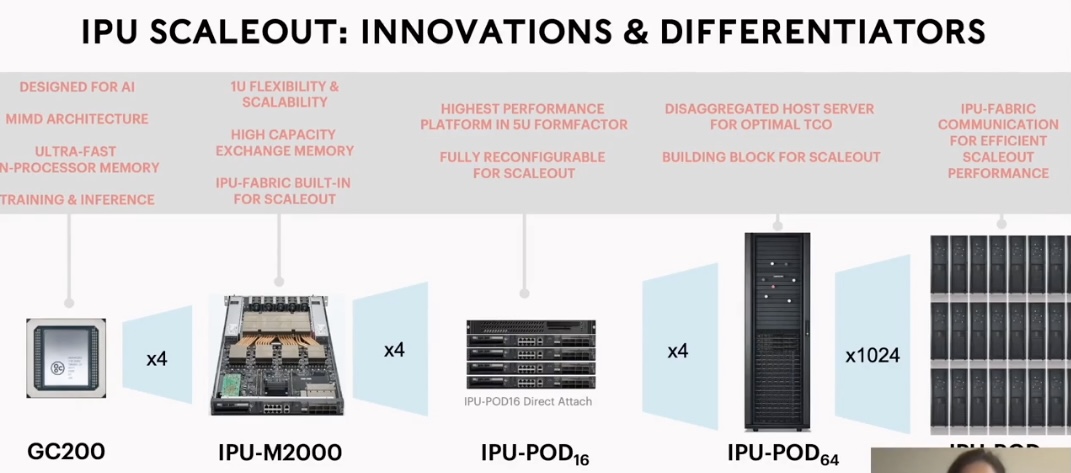
The recently introduced the MK2 Colossus, with IPU hardware designed from the ground up for machine intelligence workloads. It has a memory architecture supporting fast training and inference format.
It can be scaled all the way up to IPU-POD64, allowing us to execute massively parallel workloads at scale.
Poplar software stack
Our Poplar SDK supports widely used machine learning frameworks such as Pytorch and ONNX via the Poplar advanced runtime. The next main component of our SDK is Poplar. Poplar contains standard libraries for optimized parameters for matrix multiplication conversions, patch operators, random number generation, and communication collectors.
These are all built on top of the graph compiler and graph engine performing the core runtime capability. Poplar is abstracted away from the underlying hardware via the Poplar device interface. This abstracts away the PCIe-based system and IPU fabric systems.
We also support a wide range of platform software ecosystem products for application deployment.
Machine learning frameworks
Poplar SDK supports commonly used machine learning frameworks.

You can get a fully performant IPU target for your current machine learning models using the TensorFlow backend. We support both TensorFlow one and two, with examples and documentation on our website.

This is for targeting IPUs with simple extensions. We have multi-view support for PyTorch models. It's really straightforward to take a Pytorch model and replicate it to run on multiple devices.

This is a lightweight application runtime that's highly optimized through which you can run inference and training. It also supports model input through ONNX, and has a Python and C++ API.
Along with support for all these frameworks, we also have extensive documentation in our developer web page, and also core examples walking you through common use cases.
PopRun and PopDist
These are the libraries that support distributed training over the APS.

This is a command-line utility for launching distributed applications. It takes care of acquiring and setting up the IPUs. And it also sets up a virtual IPU partition, depending on the number of devices that you've requested.

This is a distributed configuration, Python library that you can use to configure your application to run multiple IPU jobs. It really takes care of configuring the replicas, broadcasting initial weights, and sharing the data set between the instances.
Distributed training
Multi IPU constructs
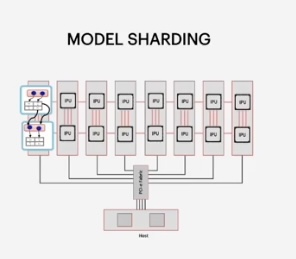
This is when a model is split across multiple devices, allowing user driven software control of model parallelism. This is fully supported in Pytorch, TensorFlow and PopART.
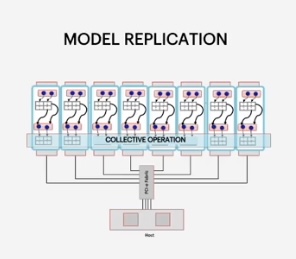
This supports the replication of models across an entire IPU system. It enables parallel training and automatic replication of models.

We also support pipelining of models across multiple IPU devices to extract maximum performance or model parallel execution.
Scaled training
Let’s say you have a very large data set on which you would like to train a computer vision model, and you'd like to use multiple IPUs. In this example, we've set up the IPU domain so that it has four instances, each with 16 IPUs. 👇
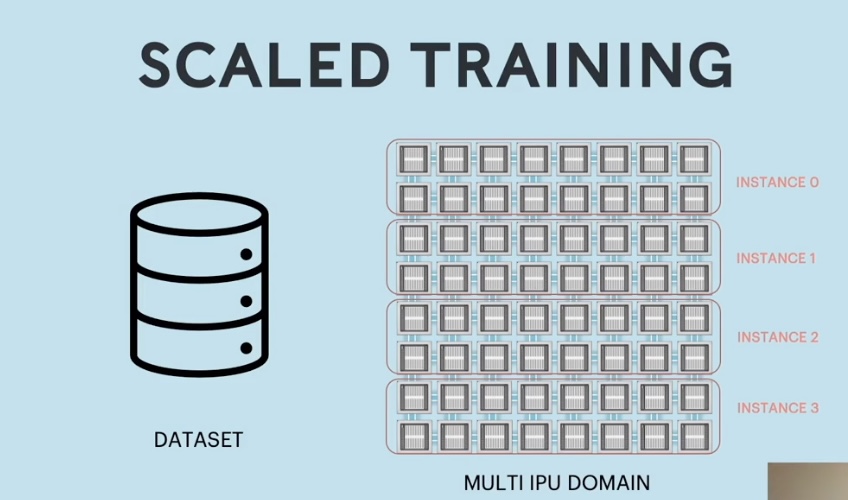
So, we're gonna run training on the system using a 64 replica IPU configuration.
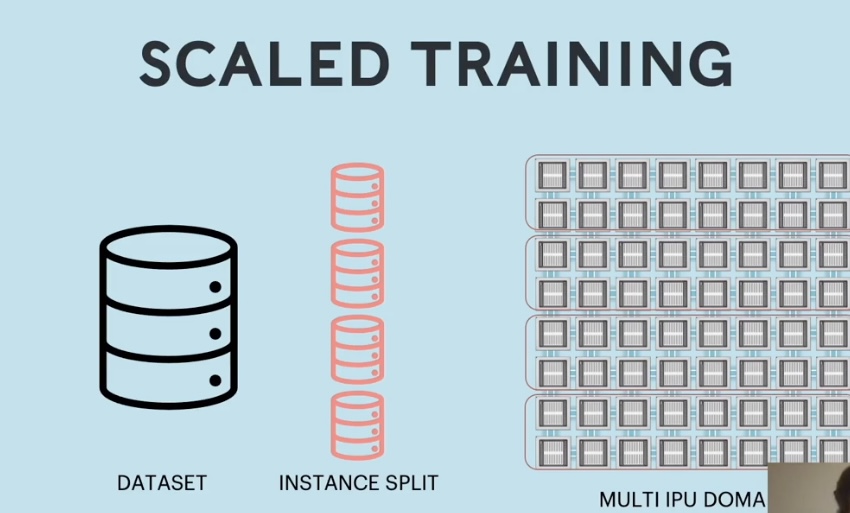
👆So, the underlying distributed training system automatically splits the dataset into four subsets, each going into a different instance.
This data set is then further split, so that each replica gets its own subset of the data. 👇

All of the replicas start with identical weights, and process a different subset of the data known as a mini batch, and compute the loss per batch. They then do the backward pass and compute the local variance per mini batch. 👇

Once we have the local gradients per replica, we perform a cross-replica weight introduction to get the total variant for that particular iteration. 👇
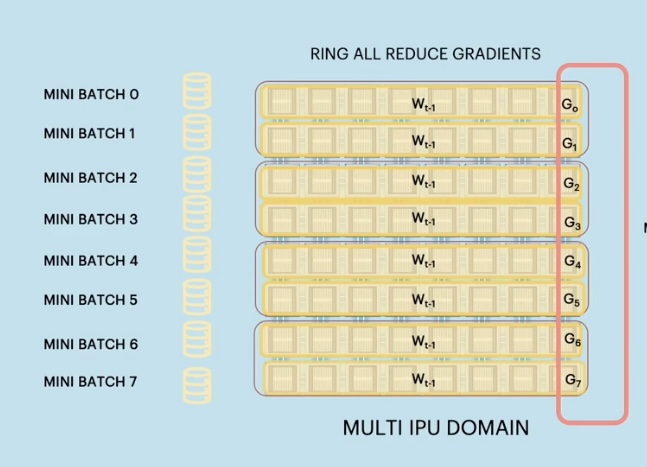
Finally, all of the replicas perform identical weight updates to compute the weights for the next step. 👇

All of the steps outlined happen out of the box without requiring the user to write any custom code to modify the training loop. So, this all happens automatically, all with very few lines of change to the actual codebase.
PopTorch code walkthrough
Next, I'll walk you through the code to show what it takes to go from an Pytorch application running on one IPU to a package application running on 64 devices.
Distributed training in PopTorch
All of the code that I'm going to show you next is coming out of our public examples on GitHub, which I will link towards the end of the article. So say you have a Pytorch model that you've managed to run on a single replica and you'd like to extend the training so that it runs on 64 devices.
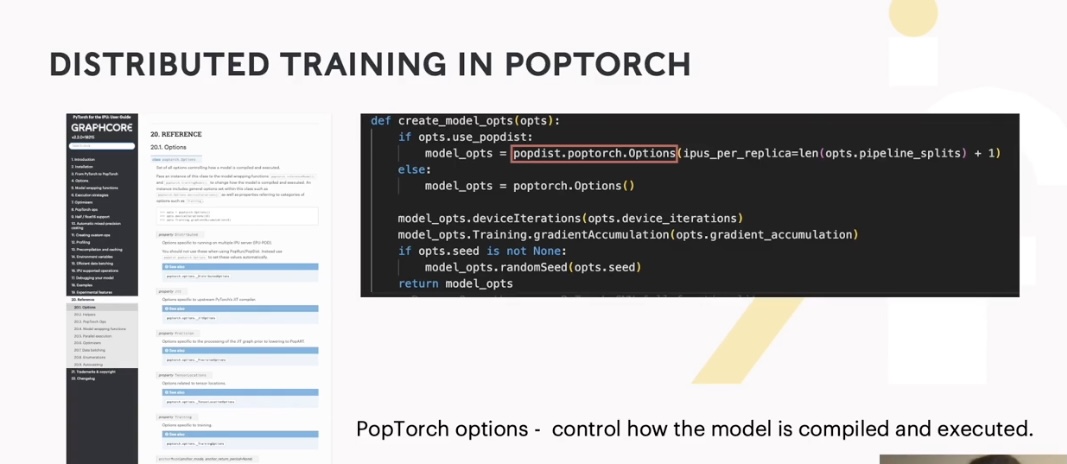
What you need to do is create a PopDist option. It needs to tell the application how many IPUs you'd like to use per replica.
This slide shows you how to take a model that is expressed in Pytorch and run it in PopTorch. All you have to do is wrap that model within this Pytorch training model and pass the actual model through the model options that we looked at in the previous slide. Then you choose the type of optimizer that you'd like to use.

Finally, within the training loop, you want to ensure that your computing metrics are across all replicas. Since you're doing replicated data-parallel training, you only need to checkpoint from one replica.
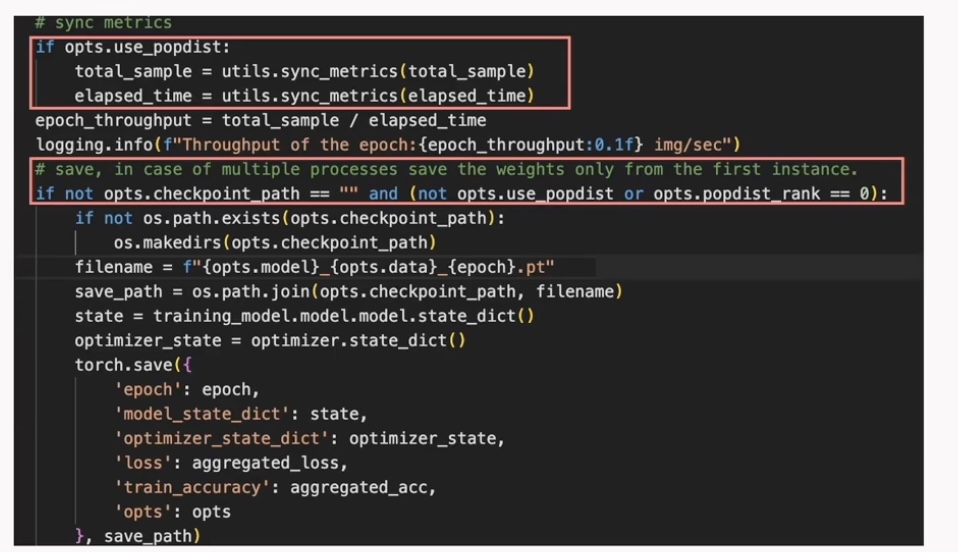
So that's it. Those are the changes that you'd need inside your application to enable distributed data-parallel training.
Launch training on multiple instances
Now that we've covered the minimal code changes that we need to run a pipe torch application on multiple devices, let's look at how to actually launch the training.
So, you could use PopRun, which is the command-line utility to launch distributed IPU applications and easily change the number of replicas that your training scheme is using. Just by prefixing this PopRun command over your Python training command, you can achieve distributed training. 👇

In this particular case, we’re training over four replicas, with each replica being four devices, and we're using four instances.
What this means is each instance has one replica. And each replica has four devices.
Poplar SDK features
Apart from the fact that it is very simple and straightforward to take a Pytorch model running on one replica and scale it up, there are a number of other popular SDK features that support distributed training.
- We support FLOAT16 training with stochastic rounding.
- In order to simulate larger batch sizes, we support recomputation and gradient accumulation.
- We support loss scaling, to make up for the loss of position when we do forward pass and backward pass in FLOAT16.
- Distributed batch normalization.
- Support for large batch optimizers such as LARS and LAMB.
- Native support for data partitioning and fast pre-processing.
- Synchronous SGD on multiple devices.
- Powerful profiling tools.
- Optimized collective libraries.
- Easy integration with monitoring tools.
Training results
Here are some training results. Typically, when you're scaling a model, going from one replica to 16 replicas, you'd expect to see identical training curves, so that you don't have to actually go and tweak any other hyperparameter. You just expect that the training goes much faster, but nothing else changes. And that's what we observe.

So, training with a single replica, or with 16 generates identical accuracy, we don't have to do any further optimization or hyperparameter tuning.
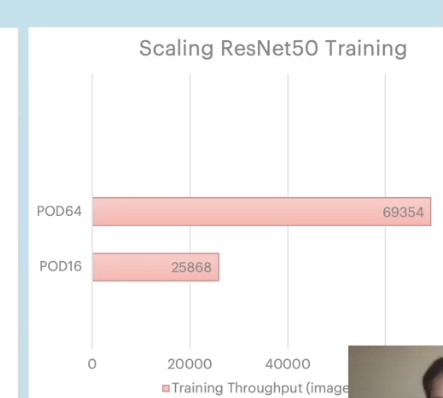
Above you can see the ResNet 50 model in TensorFlow.
On port 16, we get about 26,000 images per second, with skills up to almost 70,000 images per second on port 64. And all of this with very minimal code change. Just using PopART to change the number of replicas allows us to leverage more devices and get training to go much faster.
Resources
I'm going to leave you with some links to the developer webpage for all our documentation and SDK release information. 👇

Interested in more talks by AI experts? Sign up for our membership today.
 Richard King
Richard King


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

