
Adam Kraft is a Machine Learning Engineer at Google.
This article is adapted from the talk he gave at the Computer Vision Summit, San Jose, 2020.
Progress in Artificial Intelligence
"Let's face it. In the beginning, tools that were called artificial and intelligent, weren't really learning anything.
There were a lot of handcrafted predictions. A lot of the systems were rule-based, not necessarily learned.
Eventually, people started using machine learning to learn the predictions.
However, a lot of the features that were input into the machine learning models were still handcrafted.
Now we're currently getting to know deep learning. This is where we're learning the features and the predictions end-to-end.
A lot of people might say we are finished with ML. But, that’s not the case. There’s still a lot of handcrafting taking place.
There are people designing different architectures and different methods to pre-process the data, the algorithms, the optimizers. All these processes are still somewhat handcrafted.
Going forward, how can we really have AutoML where the algorithm, the features and the predictions are all learned and optimized?"
Why is this important?
"Many organizations that have data and uses for machine learning. Some of them are very practical and obvious.
However, there are still other organizations that don't know that they have machine learning. They have data, but they don't understand what machine learning is. Or they don't know how they can start working with it.
Also, on the practitioner side, there are only tens, or potentially hundreds of thousands of people that are trained to solve this machine learning problem. In the coming years, there's going to be organizations that have data and problems that can be fixed with machine learning.
This will mean training more people to use machine learning. But it might be tricky to keep up with the demand."
How can we meet the future demand of ML expertise and enhance current ML practitioners?
"Can the people that are currently working on machine learning use AutoML to enhance their workflow? Can it reduce their problems so that they can focus their time and energy on more important tasks in the ML process?
Also, is AutoML something that we're just striving for? Or is it something that can make a big impact in real terms.
The answer?
Yes, it is feasible. This has been shown over the past few years.
In different domains and modalities, AutoML has already made huge strides in machine learning."
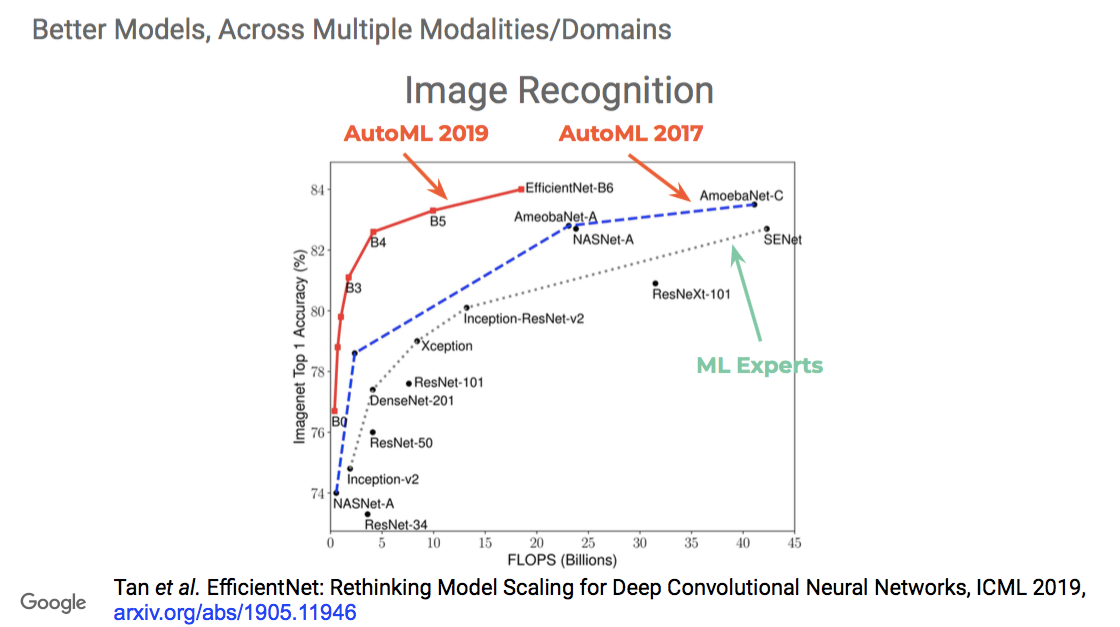
"If you look at this chart, you have the Imagenet accuracy results over many years.
A lot of these networks were handcrafted by humans who came up with different tricks to continue pushing the envelope.
In 2017, we started coming out with AutoML methods that not only matched the machine learning experts, but outperformed them.
This trend over the years is going to continue to grow."
Where can we use AutoML?
"AutoML can be used everywhere. It doesn’t just target one specific part of the machine learning process, but it solves different components.
Here's a very simple view of a machine learning development pipeline."
1) Data pre-process
"You have your data pre-processing input. How do you feed your data into your model? How do you transform it? How do you augment it?"
2) Modeling
"You have the modeling aspect. Nowadays, if using deep learning, it’s really about neural networks. How do you pick a good model that's going to work for your task? Or, how do you design one?"
3) Optimization
"On top of this, there's the optimization piece. The actual algorithm that says, given this modeling and this data, how can I learn the best parameters that will achieve the machine learning task?
Let's investigate this pipeline further."
Data pre-process
"If you think about the datasets that you have, sometimes people will augment the data so that their data set looks artificially larger.
In that case, maybe you look at another paper or example code. Maybe you look at something that's been tried in the past, where people have done some augmentations and different transformations that make sense. Or maybe you just try out some on your own and you get better results with different methods.
However, why not use a more data-driven approach?
This paper AutoAugment from 2019, shows that you can optimize the process of learning augmentation itself."

"In this case, auto-augment showed to make huge gains by using a more data-driven approach."
What about other parts of the data input pipeline?
"We know about machine learning and the need for labeled data. In other words, supervised machine learning.
But what about semi-supervised machine learning?
In practice, it is common to have labeled data alongside volumes of unlabeled data.
You'll have some pipeline to have people check or label the data. But oftentimes your systems are still getting more data in real-time that's not being labeled as quickly.
It's a common scenario where people have a set of labeled data, which could be big, could be small, but also an even larger set of data that's not yet labeled."
How can you use this?
"This is a recent work called Self-Training with Noisy Student."
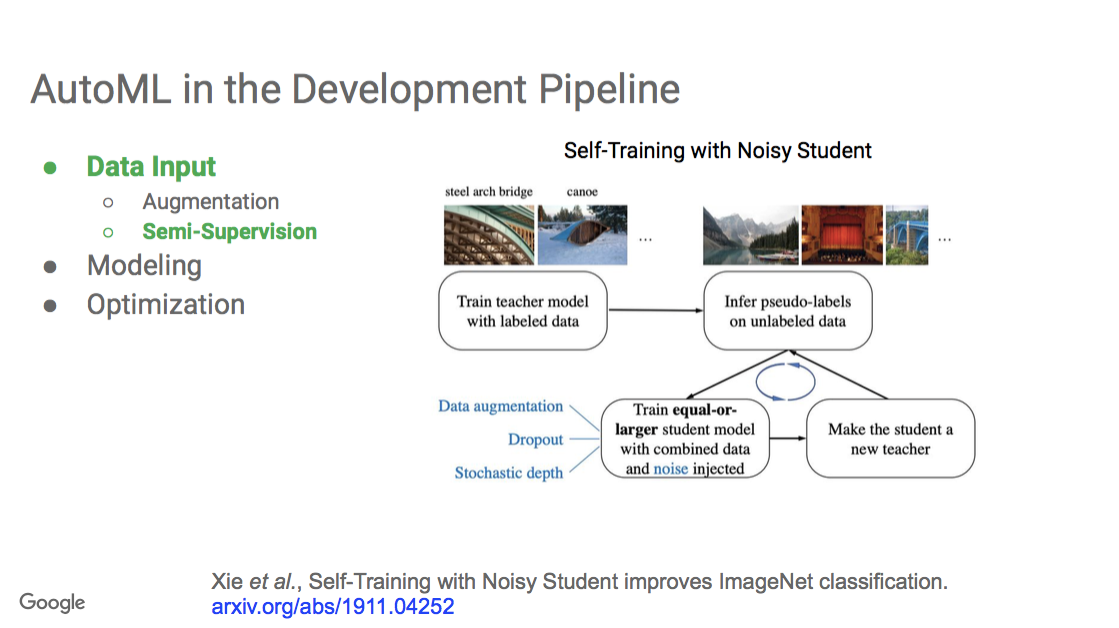
"You first learn a model on the label data that you have. You call that the teacher model.
Then you run the model on all of the unlabeled data.
On all of the unlabeled data, you create what are called pseudo labels. These are not just one class, but a distribution over the possibilities of different classes.
You have this teacher model that has added pseudo labels to this unlabeled data.
Then you train a student model, where the goal is to predict the original labels on the label data set, as well as the pseudo labels that were pseudo labeled by the teacher.
There are also other techniques where you can add noise to the system in the form of data, augmentation dropout and stochastic depth.
What ends up happening is that the student model can learn better than the original teacher on the labeled data.
You can keep doing this, iterating back and forth. First, you have a teacher that trains a student. Then that student becomes the teacher and then you train another student. In this iterative manner, you can get really good results.
This is one way where AutoML can be used to improve the data input of your system."
Modeling
"Have you ever thought about the actual functions and operations that you're using in a neural network? Oftentimes, these are available in the code that you're using.
AutoML can be used to learn new operations."
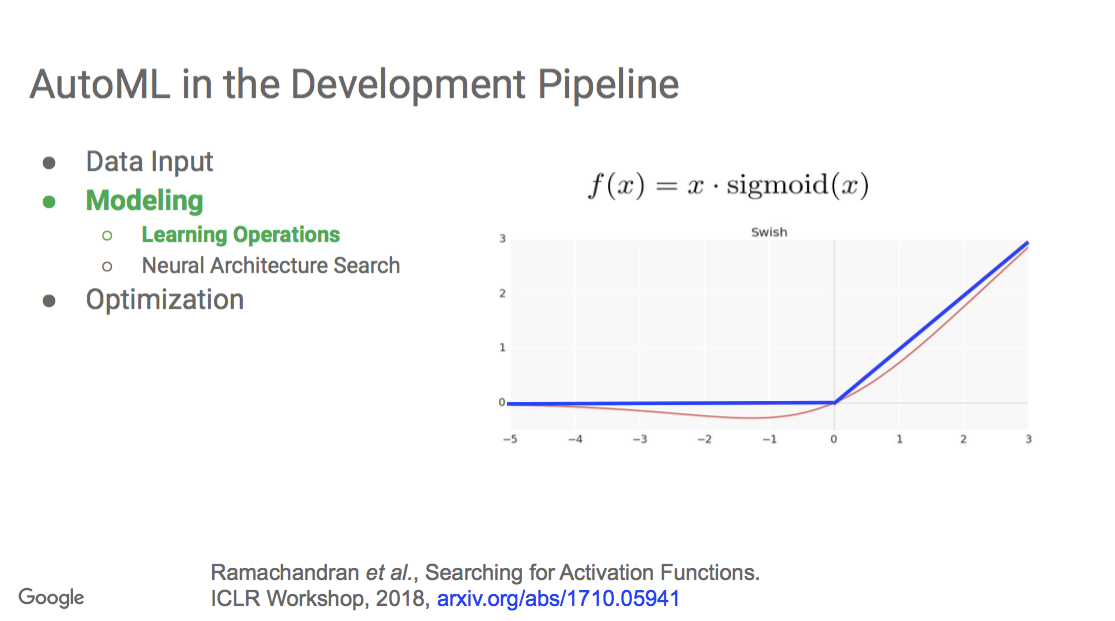
"In this example, Auto ML was used to search for new activation functions.
It learned that this function, f (x) = x · sigmoid(x ).
This is called 'Swish' and it can make improvements for many people's cases.
The image shows the blue line, a very common activation function. And the red line is what was learned.
You can think about using AutoML to design different operations of the modeling itself."
Neural architecture search
"This is an important field in the concept of AutoML. Instead of designing the network by hand and trying different parameters, there is a machine learning piece that learned different blocks within the network and how to connect them.
You get this really interesting picture of connections. It would be hard to argue that a human would purposefully design that.
This broke out in the beginning of 2017. But it has really exploded into a broad research field in terms of designing different ways to search for more interesting architectures."
Optimization
"Sometimes you'll take something off the shelf, like Adam or RMS Prop, which has these fixed update steps decided on by a human.
Even in this case, AutoML can be used to create new and interesting update rules, that can, in some cases, outperform the traditional optimizers.
AutoML is not just one aspect that's targeting one piece of your machine learning pipeline, it can be applied to many different areas."
How does it work?
"In a nutshell, AutoML is about taking your existing machine learning program and wrapping it in an outer loop.
If you have a program where you're already training something, that's what's shown in the inner loop. You have a task, you’re training it and you’re trying to get good results.
We have these different components: the controller, the parameter choices and the feedback."
The controller
"It is an acting entity. Its goal is to tell the inner loop a set of parameter choices to give the best results. After it's done, the inner loop is going to output some feedback or reward back to the controller.
The controller could be something very simple like a grid-search or a random-search. So in that sense, it wouldn't be learned. The feedback isn't going to change how the controller outputs thinks.
You can also use smarter methods such as reinforcement learning. You have an agent that's trying to output the parameter choices. It could be evolutionary-based, or it could be a gradient-based method where you're trying to optimize some set of weights in the controller itself.
The takeaway here is that if you have been exposed to some form of AutoML, you might have seen this particular method using this particular type of controller. However, there are different types of controllers and even within these, there are different ways to do reinforcement learning or evolution. There's a lot of work just on the controller aspect of AutoML."
The parameter choices
"You can think of them as knobs that the inner loop has exposed that can be tweaked.
If you're designing a neural architecture, they would be the number of convolution filters or the number of layers. They could be different augmentation operations.
Maybe it starts random, but over time, the goal is to have it tell the inner loop, 'I think these are the best set of parameters.' That's the ideal output of AutoML."
The Feedback
"The controller needs to learn. To do so it needs to get some feedback.
‘I output these parameter choices, and based on those, here's the certain feedback or the reward that I got.'
If you have an inner task that's training some classification method, a simple reward could be the accuracy of the loss, which then you're trying to either maximize or minimize.
Here you can add additional penalties. The feedback doesn't need to be just the metric itself. You can add different constraints like memory and runtime.
This is a key point.
Without constraints, your controller may just learn to output the larger options, whether that's larger filter sizes, larger numbers of layers, because those tend to get better results.
Also, if you're using a network that someone else has trained, it may not be the right choice for your system. Especially consider if you train on GPUs or TPUs, you're running on an embedded device.
It's not the case that the operations that work well on a GPU are going to be necessarily the best for your actual platform.
For your specific hardware system, you need to really think about adding constraints to the AutoML which can tune and target your particular hardware system."
Cost
"Right now, machine learning can be expensive to run even for the concept of the inner loop.
And now we're wrapping this in an outer loop. Doesn't that just drive up the cost?
The answer is yes, it can be fairly expensive. But the goal is to also show the feasibility. It’s possible for AutoML to match or exceed human experts. We can now focus on how can we drive down the cost.
One technique you can use is to shrink the cost of that inner loop.
Instead of having the inner loop train your entire data set to completion, you can use what's called a proxy task.
This can be a subset of your data or a different data set with smaller parameters to some degree. The goal is that it resembles the actual end-task that you want to optimize. If you have lower inner loop costs, you can try out more things and then hopefully arrive at a better solution.
Another idea is early stopping. Maybe the controller outputs some parameters. You start training. And you notice pretty early, ’Oh, this experiment's not going very well.' You can actually take that experiment exit early.
These methods do work.
Another concept that has gained a lot of popularity recently is called wage sharing or parameter sharing.
Here you combine the optimization of the controller and the actual task itself.
The diagram here shows how you make a design called the parameter choice or the search space."
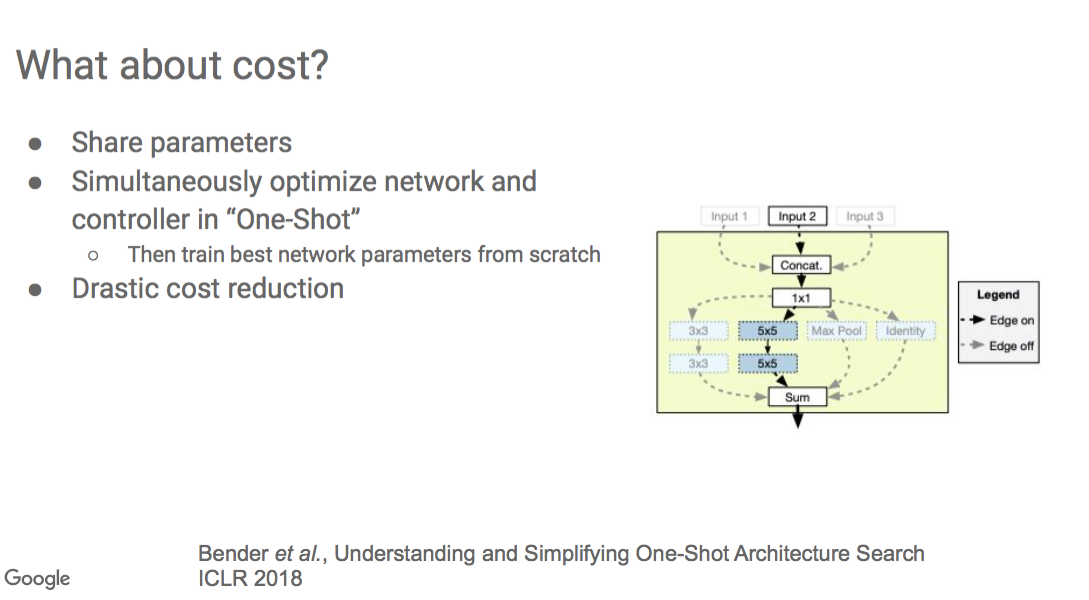
"In this case, you're trying to design a neural network architecture. You have different options.
At this point, I could do max pooling or different convolution operations. And within the convolution operations, maybe there are some different choices about filter sizes, etc.
You construct this large graph that includes all these multiple pathways.
The controller is trying to optimize its belief over the optimal path to take within the network. And at the same time, the weights of the network are being optimized such that it gives the controller more information about how useful those paths are. The controller's sampling different paths and sub-paths and making decisions and getting feedback about how those are performing, while the weights are being trained themselves.
When you do this together, you see drastic cost reduction.
Usually what happens is you simultaneously train the controller and the task itself. And then at the end, you can ask the controller, 'what is the best path? What is the best set of parameter?’ You can take the top ones and then train those from scratch on your final task."
Where are we headed with AutoML?
"In the future, AutoML will continue to expand to new applications and tasks. It's already had a significant impact on video, computer vision, texts, tabular data and more. AutoML can exceed ML experts at many different tasks. It allows non-experts to solve machine learning problems.
But, can we push into new areas? How do we lower the barrier to entry for people that want to use machine learning?
There are important industries that have very smart people working on pressing issues such as climate change and deforestation. How can they also get ML expertise on hand?
When the cost goes down for AutoML, the barrier is lowered for machine learning tasks. Hopefully AutoML will continue to drive down some of these costs for machine learning.
I've touched on some different components of AutoML. Maybe I've educated a few of you on what it is or where it can be applied. I hope that the community continues to expand and that people become more familiar with these concepts."


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

